Why the Heck is Git so Hard? The Places Model™
… ok maybe not hard, but complicated (which is not a bad thing)
This post is aimed at those programmers having experience with SVN (or CVS) and who are about to embark upon learning Git. Your road ahead will be complicated.
The post will show that one of the reasons (there are other) why going from the SVN model of source-control to Git can be so complicated comes from the fact that there are many more places for source to exist. Rather than focusing on the warts, I hope this post will explain to newcomers the Places Model that will help motivate why Git is complicated (and yet amazing).
This model is one of the most important thing to understand about Git -- and memorize. The actual command-lines are the arcana of accretion and arbitrary conflation, and are one of the reasons people get so frustrated with Git. Just use stack-overflow. Or even better, use this beautiful site.
SVN is Relatively Simple
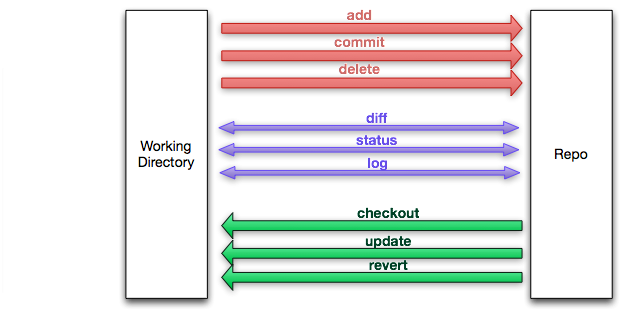
In SVN there are only two different places source can exist: your local directory and the remote repository. All our interactions back and forth (checking out, committing, reverting, status) are between these two places. This is not too difficult to understand. If we have N different interactions, then we only have to understand these N-interactions.
In the above diagram, I show three types of interactions for a SVN system. Red interactions move source from the working directory place to the repository place. Green interactions move source in the other direction (from the repository to your working directory). And purple interactions are useful for getting information about both places. In this post we are going to ignore branching.
Git: Increasing Places and Increasing Interactions
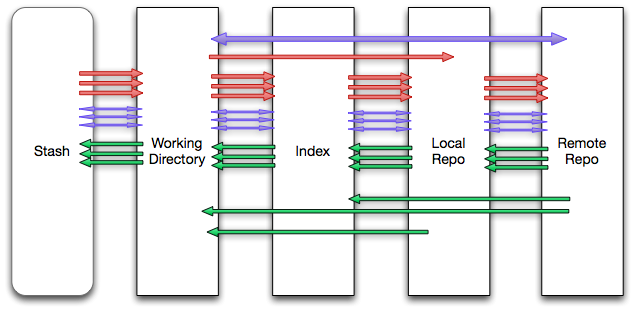
In Git, there are five places your source can exist:
a stash,
your local working directory,
an index (or staging area),
a local repository,
and a remote repository.
Knowing that these places even exist is often the first conceptual impediment for someone coming over to Git from SVN.

Why do these Places Exist?
These places are part of the power and flexibility of Git over other systems.
With an index, we can choose how to commit a multitude of changes, without having to commit to all our changes at once. This is a great flexibility. With the local repository versus the remote repository, we turn Git into a distributed version control system, where each repository is conceptually just as equal to the next one. With stash, we take advantage of the underlying content DAG to provide us an amazing convenience.
|
In between all of these places, we can (loosely) have the same types and number of interactions. If we assume a well-orderedness to these places then we have to minimally concern ourselves with N*4 interactions.
It’s not actually as many as N*4, as a lot of these operations don’t really occur that often (or at all), and because the ‘stash’ is not used that often (or, more accurately, is optional). On the other hand, to increase our numbers, we also acknowledge that many interactions interact with multiple places at the same time, or between places that are not next to each other (consider git pull, for instance). In short, there are many more interactions that can be occurring. A lot more than N.
This is the first great step to attaining enlightenment in Git:
Knowing that there are many more interactions, gives you a framework to understand the bad parts of Git, the names of these interactions. I highly suggest you use cheat-sheets like this while you are learning. I am not going to debate anyone about this. It is a personal opinion that I hold, and I am comforted in knowing that I share this opinion with many others: the command-line usage is a pain in the butt.
If anything, the Places Model is not the reason Git is so hard. Git is so hard because of the lack of clear mapping between the command-line and Git’s underlying models: places, content, branching, and remotes.
You have been introduced to the first step in Git enlightenment: the Places Model™.
You are Not Done!
The second step in attaining enlightenment in Git is learning the Content Model. Therein contained is knowledge of the objects of commits, blobs, trees, tags and the pseudo-objects of everything else: refs and refspecs, SHA’s, etc.
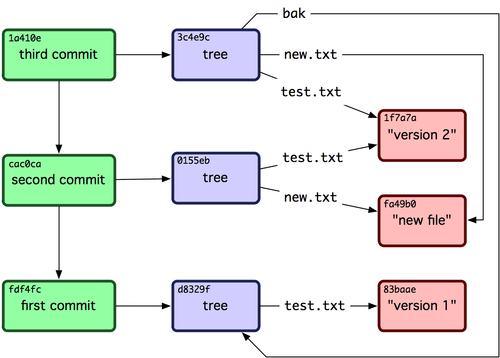 |
| The Content Model |
The third step is learning the Branch Model. The Branch Model is built atop of the Content Model but follows the evolution of commits as they provide temporal DAG-like capabilities (aka ‘versioning’).
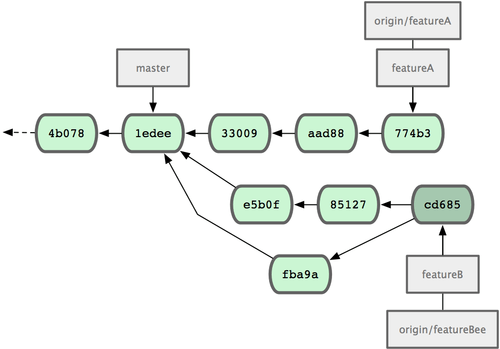 |
| The Branch Model |
This post will not seek to explain these next steps. There are many other online books and posts which cover the fact that Git is essentially a DAG of content-hashed pointers to file contents (a content-addressable versioned file system all hidden in your .git directory). I suggest the following to get you started:
-
-
-
-
Once you have a true understanding of these models, working with Git becomes easier. Your day to day activities can now be understood within the context of manipulating your source through the temporal and spatial landscape that these models provide.
 One could argue that there is actually a fourth step, which is a mixture of the Places Model and the Branch Model, in which we concern ourselves with the lifecycle and availability of branches in different places: the Remote Model. One could argue that there is actually a fourth step, which is a mixture of the Places Model and the Branch Model, in which we concern ourselves with the lifecycle and availability of branches in different places: the Remote Model.
Understanding remote refs and how tracking branches work is a first step in the Remote Model. This model is also the source of a lot of opinion, best-practices, and team-building. If you have ever heard of git-flow, the git rebase versus git merge debate, and private versus public branches, then this is the realm of the Remote Model. It is also here that you will have enter the hosted world of GitHub and its competitors.
|
Good luck on the winding road ahead. Maybe one day you can be involved in something like this.
Personal Context For Wanting to Write this Post
I have been using Git since about 2007 (6 years now). I am not great at it, mainly because I have not used it constantly. I often go months without programming or am forced to use a client’s source control system.
 Previous to Git, I had researched other distributed VCSs like Monotone and Darcs. I even released my only-ever open-source project, back in 2006, from a Darcs repository (I still love the elegance of the Darcs model and command-line). In the end Git and Mercurial are the ones that have flourished. (Yes. I know bazaar and monotone are out there). Previous to Git, I had researched other distributed VCSs like Monotone and Darcs. I even released my only-ever open-source project, back in 2006, from a Darcs repository (I still love the elegance of the Darcs model and command-line). In the end Git and Mercurial are the ones that have flourished. (Yes. I know bazaar and monotone are out there).
Having to go months without using Git and then coming back to it, I am constantly reminded of how complicated it is. Inevitably I have to review git reset and tend to forget when to use git checkout versus git branch. If my memory were better perhaps I wouldn’t be writing this post.
I am in awe of Git’s promiscuous branching, speed, flexibility, and distributed nature. The versioned content-addressable file-system and DAG that underpins the repository was a genius choice, and one that was even controversial in the beginning. Previous systems stored and calculated deltas.
With all that there is to like about Git, I have always been so frustrated at the lack of clarity in the command-lines for doing anything beyond the simplest action. Heck, even the simplest actions are harder than they need to be.
The history of Git shows that Mr. Torvalds set about building the underlying file-system content model with the assumption that eventually a good front-end would be built. In the end, the front-end was accreted into existence and is the one everyone uses today. I often wonder how tolerant defenders of the Git command-line would be if they didn’t have StackOverflow when they were learning.
Perhaps somebody will provide an alternate front-end to the Git places model that fully acknowledges the places and the interactions as first-class citizens. It might be a naive concept, but having a command-line that did something like
git --from INDEX --to REPO --interaction COMMIT
would at least match the underlying places model. Obviously there are hundreds of subtleties I am overlooking, and I am sure such an effort has probably been done before™.
|
UPDATE !
As someone in the comments below mentioned there is another beautiful site out there that focuses on the Branch Model. I highly suggest you go to this link http://pcottle.github.io/learnGitBranching/ and see how utterly skilled people can be with javascript. You can interactively explore the Commit DAG and see how rebases, merges, checkouts and resets work.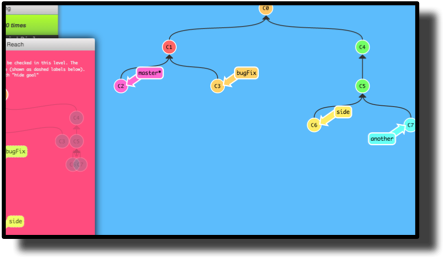
In my following post, I had put together a mini-animated gif to show something similar, but I think this site does a much better job.
However, what neither my animated gif nor this site show is how most commands modify the models at the same time, e.g. how the Places Model is affected by such things as git reset with options like --soft, --hard, --merge, --mixed modifying your index and/or working directory. In fact, the subtleties involved in knowing that different types of git resets are not only modifying your Branch Model (where your HEAD-branch pointer resides) but simultaneously your Places Model, lead to a lot of confusion. This StackOverflow answer is the one that I still refer to.
I think there is a place for a good visualization (animated or not) that shows how both models are affected by each type of git command at the same time
|