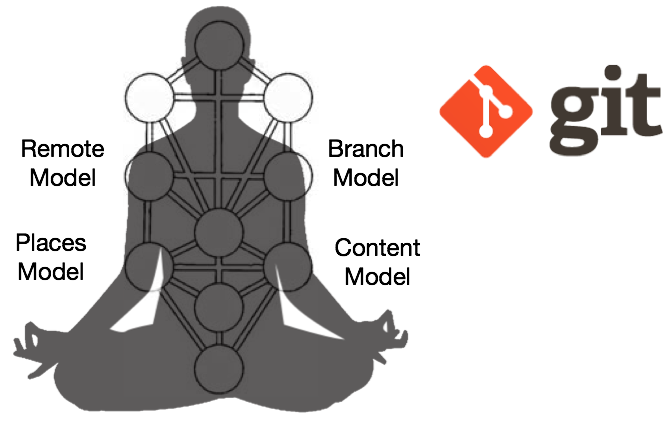
Why the Heck is Git so Hard? The Places Model™
… ok maybe not hard, but complicated (which is not a bad thing)
This post is aimed at those programmers having experience with SVN (or CVS) and who are about to embark upon learning Git. Your road ahead will be complicated.

The post will show that one of the reasons (there are other) why going from the SVN model of source-control to Git can be so complicated comes from the fact that there are many more places for source to exist. Rather than focusing on the warts, I hope this post will explain to newcomers the Places Model that will help motivate why Git is complicated (and yet amazing).
This model is one of the most important thing to understand about Git -- and memorize. The actual command-lines are the arcana of accretion and arbitrary conflation, and are one of the reasons people get so frustrated with Git. Just use stack-overflow. Or even better, use this beautiful site.
This model is one of the most important thing to understand about Git -- and memorize. The actual command-lines are the arcana of accretion and arbitrary conflation, and are one of the reasons people get so frustrated with Git. Just use stack-overflow. Or even better, use this beautiful site.
SVN is Relatively Simple
In SVN there are only two different places source can exist: your local directory and the remote repository. All our interactions back and forth (checking out, committing, reverting, status) are between these two places. This is not too difficult to understand. If we have N different interactions, then we only have to understand these N-interactions.
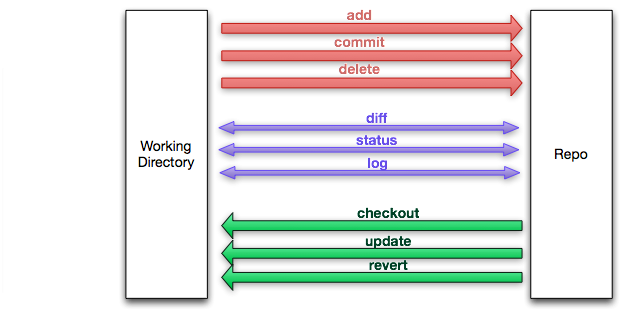
In the above diagram, I show three types of interactions for a SVN system. Red interactions move source from the working directory place to the repository place. Green interactions move source in the other direction (from the repository to your working directory). And purple interactions are useful for getting information about both places. In this post we are going to ignore branching.
Git: Increasing Places and Increasing Interactions
In Git, there are five places your source can exist:
- a stash,
- your local working directory,
- an index (or staging area),
- a local repository,
- and a remote repository.

Why do these Places Exist?
These places are part of the power and flexibility of Git over other systems.
With an index, we can choose how to commit a multitude of changes, without having to commit to all our changes at once. This is a great flexibility. With the local repository versus the remote repository, we turn Git into a distributed version control system, where each repository is conceptually just as equal to the next one. With stash, we take advantage of the underlying content DAG to provide us an amazing convenience.
|
In between all of these places, we can (loosely) have the same types and number of interactions. If we assume a well-orderedness to these places then we have to minimally concern ourselves with N*4 interactions.
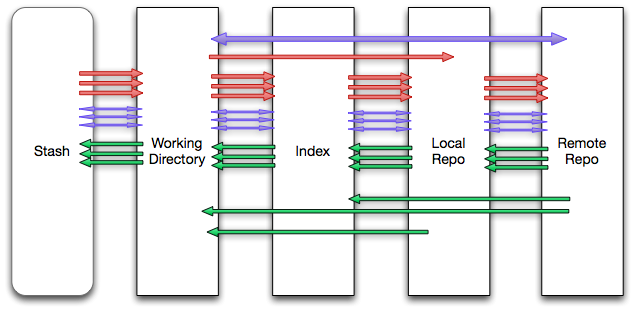
It’s not actually as many as N*4, as a lot of these operations don’t really occur that often (or at all), and because the ‘stash’ is not used that often (or, more accurately, is optional). On the other hand, to increase our numbers, we also acknowledge that many interactions interact with multiple places at the same time, or between places that are not next to each other (consider git pull, for instance). In short, there are many more interactions that can be occurring. A lot more than N.
This is the first great step to attaining enlightenment in Git:
This is the first great step to attaining enlightenment in Git:
- knowing that there are five places
- 3 that we use all the time, (working directory, index, and local repo)
- 1 we use when we interact with teams or want to back-up (remote repo)
- 1 that we can use optionally as much as we like (stash)
- and knowing that there are many interactions that can occur between these places and sometimes between more than two places simultaneously.
Knowing that there are many more interactions, gives you a framework to understand the bad parts of Git, the names of these interactions. I highly suggest you use cheat-sheets like this while you are learning. I am not going to debate anyone about this. It is a personal opinion that I hold, and I am comforted in knowing that I share this opinion with many others: the command-line usage is a pain in the butt.

If anything, the Places Model is not the reason Git is so hard. Git is so hard because of the lack of clear mapping between the command-line and Git’s underlying models: places, content, branching, and remotes.
You have been introduced to the first step in Git enlightenment: the Places Model™.
You have been introduced to the first step in Git enlightenment: the Places Model™.
You are Not Done!
The second step in attaining enlightenment in Git is learning the Content Model. Therein contained is knowledge of the objects of commits, blobs, trees, tags and the pseudo-objects of everything else: refs and refspecs, SHA’s, etc.
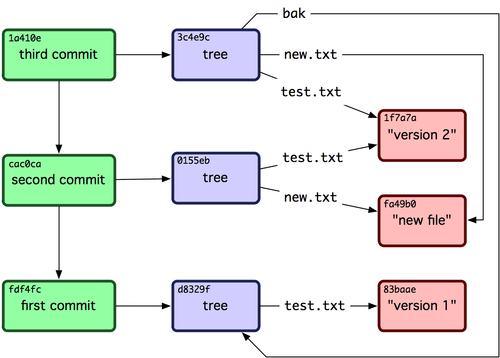 |
| The Content Model |
The third step is learning the Branch Model. The Branch Model is built atop of the Content Model but follows the evolution of commits as they provide temporal DAG-like capabilities (aka ‘versioning’).
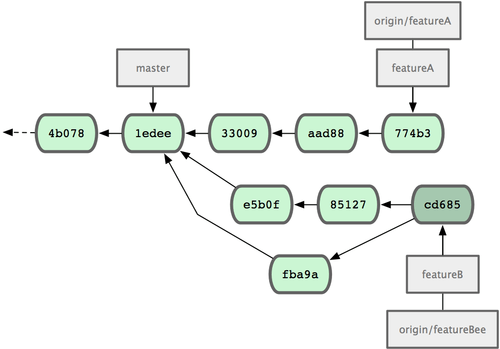 |
| The Branch Model |
This post will not seek to explain these next steps. There are many other online books and posts which cover the fact that Git is essentially a DAG of content-hashed pointers to file contents (a content-addressable versioned file system all hidden in your .git directory). I suggest the following to get you started:
Once you have a true understanding of these models, working with Git becomes easier. Your day to day activities can now be understood within the context of manipulating your source through the temporal and spatial landscape that these models provide.
 One could argue that there is actually a fourth step, which is a mixture of the Places Model and the Branch Model, in which we concern ourselves with the lifecycle and availability of branches in different places: the Remote Model. One could argue that there is actually a fourth step, which is a mixture of the Places Model and the Branch Model, in which we concern ourselves with the lifecycle and availability of branches in different places: the Remote Model.
Understanding remote refs and how tracking branches work is a first step in the Remote Model. This model is also the source of a lot of opinion, best-practices, and team-building. If you have ever heard of git-flow, the git rebase versus git merge debate, and private versus public branches, then this is the realm of the Remote Model. It is also here that you will have enter the hosted world of GitHub and its competitors.
|
Good luck on the winding road ahead. Maybe one day you can be involved in something like this.
Personal Context For Wanting to Write this Post
I have been using Git since about 2007 (6 years now). I am not great at it, mainly because I have not used it constantly. I often go months without programming or am forced to use a client’s source control system.
 Previous to Git, I had researched other distributed VCSs like Monotone and Darcs. I even released my only-ever open-source project, back in 2006, from a Darcs repository (I still love the elegance of the Darcs model and command-line). In the end Git and Mercurial are the ones that have flourished. (Yes. I know bazaar and monotone are out there). Previous to Git, I had researched other distributed VCSs like Monotone and Darcs. I even released my only-ever open-source project, back in 2006, from a Darcs repository (I still love the elegance of the Darcs model and command-line). In the end Git and Mercurial are the ones that have flourished. (Yes. I know bazaar and monotone are out there).Having to go months without using Git and then coming back to it, I am constantly reminded of how complicated it is. Inevitably I have to review git reset and tend to forget when to use git checkout versus git branch. If my memory were better perhaps I wouldn’t be writing this post. I am in awe of Git’s promiscuous branching, speed, flexibility, and distributed nature. The versioned content-addressable file-system and DAG that underpins the repository was a genius choice, and one that was even controversial in the beginning. Previous systems stored and calculated deltas. With all that there is to like about Git, I have always been so frustrated at the lack of clarity in the command-lines for doing anything beyond the simplest action. Heck, even the simplest actions are harder than they need to be. The history of Git shows that Mr. Torvalds set about building the underlying file-system content model with the assumption that eventually a good front-end would be built. In the end, the front-end was accreted into existence and is the one everyone uses today. I often wonder how tolerant defenders of the Git command-line would be if they didn’t have StackOverflow when they were learning. Perhaps somebody will provide an alternate front-end to the Git places model that fully acknowledges the places and the interactions as first-class citizens. It might be a naive concept, but having a command-line that did something like git --from INDEX --to REPO --interaction COMMIT
would at least match the underlying places model. Obviously there are hundreds of subtleties I am overlooking, and I am sure such an effort has probably been done before™.
|
UPDATE !
As someone in the comments below mentioned there is another beautiful site out there that focuses on the Branch Model. I highly suggest you go to this link http://pcottle.github.io/learnGitBranching/ and see how utterly skilled people can be with javascript. You can interactively explore the Commit DAG and see how rebases, merges, checkouts and resets work.
In my following post, I had put together a mini-animated gif to show something similar, but I think this site does a much better job. 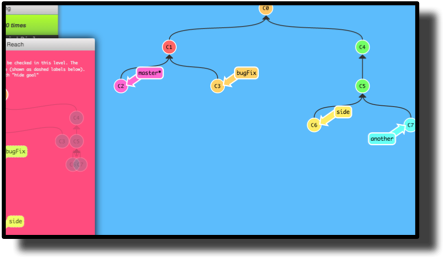 However, what neither my animated gif nor this site show is how most commands modify the models at the same time, e.g. how the Places Model is affected by such things as git reset with options like --soft, --hard, --merge, --mixed modifying your index and/or working directory. In fact, the subtleties involved in knowing that different types of git resets are not only modifying your Branch Model (where your HEAD-branch pointer resides) but simultaneously your Places Model, lead to a lot of confusion. This StackOverflow answer is the one that I still refer to. I think there is a place for a good visualization (animated or not) that shows how both models are affected by each type of git command at the same time |
The biggest problem for me to move from SVN to Git was absence of good git app (with good UI) to manage local resources and synchronize with remote sotrage. When I discovered Source Tree or Smart Git I want use git for all projects.
ReplyDeleteThe reason why SVN users find git so hard is because of the comparison that comes naturally to us. Which is what you have done in this post mostly. SVN is subversioning, so is git. They should not be that different? Right?
ReplyDeleteWell, no. Because with git, there is an inherent change in the philosophy of subversioning. The whys, whats and hows changed. This is the reason why git exists in the first place. SVN does not provide what coders need. It is mostly used to share code with other devs, build servers. Try branching for a new feature and merging it back to the trunk. THAT is a pain in the ass. The wide acceptance of git by the dev community is a proof that git's philosophy won over SVN's.
Most of the initial pangs SVN users face are because they are not used to the flexibility that git provides. It's like taking a slave and putting him in a free country. With SVN you could do only 5 things and there were 5 neat buttons in a flashy UI to do it. With git you can do a 100. There a local? There is a remote? What the heck is a stash? Those are the things that confuse you. But then why do you know about a stash if you don't have the need for it? Most of your problems are explained by your context. Since you don't need to code that frequently, git's powers are lost on you. Not so with someone who does a hundred commits a day. :)
I suggest that any new git user approach git afresh and forget about SVN. That will make his/her life easier. Check out the first three chapters of http://git-scm.com/book . Also, don't explore a feature unless you need it.
Personally I'm tired of learning whole new philosophies every time someone decides to build an app. I just want it to work. Perhaps I'm just impatient, but I am here to complete applications not prove how awesome my knowledge of "the force" is. In the first 10 years of programming that was important to me, but now I just want to complete projects and make some $.
Delete+++ bingo
DeleteExactly
DeleteYes - this guy
Delete+1
DeleteI just want to get my work done. Do they think I would give priority to learning Git, over learning Spring or Hibernate or Hadoop?
A good version control system should just do its job and get out of the way.
BTW, whats with that easy branching with Git? Now there are local branches and remote branches? I dont think it is less complicated than SVN. I have never used SVN branching extensively, but I remember simply sending a request to the SVN admin to create a branch, and it was done in minutes !
>>> Personally I'm tired of learning whole new philosophies every time someone decides to build an app
Unless it is improving my productivity or letting me achieve something more. Is Git increasing my productivity or doing more than version control?
+++++++++++++++++++ amen.
DeleteAll this new crap is by people who don't want to learn the old and they spend huge amounts of time reinventing the wheel rather than improving what's already there and it puts the rest of us through hell.
This comment has been removed by the author.
DeleteYes sir, Git is made by a geek and its main audience seems to be geeks, not developers. It seems to care more about "showing the force inside the master" than being pragmatic and fulfilling requirements/needs.
DeleteFinally someone with a brain! just get the job done, who cares how intellectually superior or inferior one source control over another. I don't understand all the fuss about it.
DeleteI do not want to edit the internal files of my revision system. I want to make a modification and push it so others can use it.
DeleteI been a developer for 20 years, and I want to:
1. Get the code
2. Update the code
3. Secure the code at same site I got it from
Why in hell should I need to know the internals of GIT, I do not need to know the internals of the JVM to use Java (I do know it, but I shouldnt need to)
I dunno guys. Initially, a few years ago, I shared your opinion as it seemed excessive compared to SVN. Indeed, as (mostly) a lone developer, I am not sure it has greatly benefited my life, but I do love the ability to create local repository on the fly without having to create a new SVN repository. And you don't *have* to get all complicated with Git. You can use it in a similar way to SVN without a whole lot of fuss. When necessary, you can get more advanced. The largest reason to adopt it is indeed the proliferation of Git itself. You just have to these days, especially if you do any F/OSS work. Use of anything else will get a puzzled response by younger developers, and anyone who has made the switch for that matter. It is a new standard. Like it or not. Of course, nobody is forcing you to use it if you don't find it beneficial to your productivity.
DeleteYou nailed it on the head Jeremy, "The largest reason to adopt it is indeed the proliferation of Git itself." Not because it is better, but because everyone is doing it is the only reason git matters. I often wonder if Linus Torvalds wasn't the creator if it would have picked up any steam. Still garbage and less productive. It's not how good your product is, it's how good your marketing is.
DeleteWho are you to speak for others? I believe SVN is actually exactly what developers need and git is retarded. Also you can do branches in svn. If you want locally you can copy paste the folder. simple right?
DeleteFor git branching, learn it here:
ReplyDeletehttp://pcottle.github.io/learnGitBranching/
wow. phenomenal
DeleteThe difficult thing about git for me is that I've seen so many "git workflow" blog posts, and yet I've never seen two people that have the same workflow. It's like Perl, there are a million ways to do something, which can make it difficult to learn.
ReplyDeleteThe best thing about git is that it keeps away the riffraff coders since it's so hard to learn. I propose that the next version of git is even more abstract, harder and shittier to use, so that only the most elite of programmers can use it. That way, the quality of open source software will skyrocket while the quantity of projects will dramatically drop, making it much easier to find what remains.
ReplyDeleteWell I could laugh if I didn't have to cry. Maybe there are people writing software for many many years, who have seen VCS'en come and go. GIT is basically just another barrier to be productive. It makes you shift focus from programming to fooling around with an arcane and plain weird command line that just moves bits around on your disk. In other words, it does not add anything to your project, except much more storage and hassle.
DeleteI agree that the underlying technology is fantastic and ideal for collabarating with many people but my God, the interface is horrible. Everytime I use it I feel like I'm polluting my internal namespaces, causing brain damage.
So, while you're playing around with your new file-copying toy that has a lot of buttons, I'll be releasing my latest projects and meanwhile be on the lookout for better distributed VCS that has a sane interface. Thank you!
Then you're doing it wrong.
DeleteI've been at this for close on 2 decades, and git is one of the most industry changing tools to ever cross my path because it helps protect me from ... me.
I'm one of the 99% developers who are sloppy, human and with a short attention span. It may have taken a little work to get my head around dvcs and git in particular but it's paid back in spades.
If it's visual tools you want there are plenty of good ones now - TortoiseGit on Windows, SourceTree on Windows and Mac, and the one integrated into the JetBrains IDEs are all superb.
No, he/she is thinking correctly. Git is a productivity killer. The mass cult-like worship of it stems from something endemic to the development world, that is, the ( often macho ) need to find tools that are difficult for the sake of being so. It introduces a cool factor because you spent every night and weekend learning the byzantine procedures and it makes you feel superior to the plebes. Meanwhile, us plebes are busy either working on useful things like, oh, our applications or enjoying some time out in the fresh air.
DeleteGit is a powerful tool, but its flexibility is its fatal flaw. It is not well-structured in making the most important operations simple to use and being transparent to your main work. It requires far too much mental cycles for regular usage, the syntax is terrible, worrying about all these places where data is and what state its in, and how easy it is to get your data screwed up ( it happens far more than git lovers will every admit. I've had it lose files that were never recoverable several times this year alone ) and waste yet more time untangling the mess...
Unfortunately, it's not the first time a bad solution has become the standard. We can only hope a better one will come along.
Agreed it is awful, even comparing two versions of the same file together that are checked in is so painful.
DeleteThe best version control software I have used in the last 20 years is Starteam
"Then you're doing it wrong." Someone take whoever wrote that comment above and nail them to a wooden post.
DeleteA tool is supposed to help me do my job, and when it comes to source control it's also supposed to help confine a team to a manageable process. In both of these things, Git fails miserably.
Git is a waste of time that fills one with uncertainty and dread whenever something goes wrong. And it does, all the f(((g time.
Just the other day we discovered one external dev pushing from repo A to repo B, by physically copying his filesystem from folder A to folder B and forcing commits. No warnings, no complaint, nothing. No management. Why no management? Because GIT is not something management understand? Doing it wrong? Tell the f(((g management.
Really I do not see why people find git so hard. Once I spent less than a week getting used to it, and knowing how to use its features, its been a complete non-issue for me. I don't even think about it while I am using it.
DeleteWhats so hard about git pull, git branch, git merge etc?
>> even comparing two versions of the same file together that are checked in is so painful.
Delete+1
>> Whats so hard about git pull, git branch, git merge etc?
at least it is much easier to merge your local changes and whats on the repo with SVN. With Git, I have three - working dir, local repo, and remote repo.
This comment has been removed by the author.
DeleteNo one should be allowed to say that GIT it GREAT, unless they had:
DeleteA days worth of work in a uncommitable "undetected branch" state!
Cause after they had that, if they still say git is great, they are clearly liers!
github is a complete waste of time...why spend your time working on a complicated system and a programmers ego which could have been used actually creating useful projects and programs!!!
ReplyDeleteWhat a disgrace
Untalented programmers like Git because they can spend their time mastering a ridiculous workflow instead of producing actual work, which they are unable to do.
ReplyDeleteThis comment has been removed by a blog administrator.
ReplyDeleteI tell you a true story.
ReplyDeleteFor my personal solo project, i use GIT. I have no choice because OpenShift, Appfog, Visual Studio Online need it.
However, on my workplace, I am a project lead of a team with 10 peoples (programmer and web designer).
Day 1, every people agree using GIT, why?
Because everyone is excite on GIT, which is a famous and brand new VCS. (on 2011)
About 6 month, i hear some of them complain, they spend time to do commit/push/fetch/pull/rebase and resolve the conflict!
So finally, i stay with SVN and everything more simple, commit and update ,done.
We still use CVS because it is even easier to use, fully supported by almost every old and new IDE and it just works and it's easy to make backups of it or SVN to recover from anytime.
Deletethe problem with GIT is that you AHVE TO learn A LOT of things before you can even USE IT
ReplyDeletewhereas to SVN the common sense is enough to save you without actually learning online
=> anyone would understand a checkout or commit in SVN
but in git .... no
so it might be in the future a good tool but the command line is AWFUL
not consistent, not explicit, and confusing
example : a checkout or checkin ... anyone says ok i get it
but in git you can't guess you HAVE TO KNOW a lot of tricks
i do use and know git because of i am FORCED to use it at work...
i would not advice it for a project though for the simple reason that developers , at least some
are not comfortable to do simple things like checking it, out, diff...
using command lines and bottom line is (whatever the reason could be)
what takes 1 click in SVN takes 10 minutes and 5 thoughtfully crafted lines in git for a "non expert"
which is most people ...
so yes the model is more powerful but no don't use it yet
wait for a good UI and MAYBE it ll be worthing it
and i believe 95% of the time pole do not need distributed
and a clear simple UI would be one hiding things such as the distributed layer of it...
to fall back to a SVN like UI
Before concluding that Git's complexity is warranted to solve the problem of distributed version control, check out Mercural and Bazaar. While Git is certainly faster than both of these, the others are orders of magnitude easier to use, approaching the ease of use of Subversion with all the benefits of distribution.
ReplyDeleteI don't think lots of Git users have given these systems a serious try, or are so far embedded in Git thinking that they see all the shortcomings of Git as the "right" way to do things, regardless of the needless complexity involved. Complexity however is not Git's worst crime - the bigest problem with Git is that it gets the branching model completely wrong.
See this older post about Mercurial named branches vs Git branches: http://jhw.dreamwidth.org/2049.html
And this more recent post comparing git/hg/bzr branching: http://duckrowing.com/2013/12/26/bzr-init-a-bazaar-tutorial/
With either Mercurial or Bazaar, you can get the benefits of DVCS without Git's headaches.
Git is such a huge overhead. Never had any major problems with SVN Everything is lucid and folder based. All those message i see in git about rebasing, forced commit not allowed, pulling, push make me sick
ReplyDeleteFinally some people not raving about how good GIT is.
ReplyDeleteThe progress of technology can be understood in terms of efficiency. If a new tool can make someone or something more efficient in some way then it will be successful and will stick around. This is why societies are tending towards becoming just-in-time with little redundancy if things go wrong. Redundancy equals cost. It also explains why jobs become increasingly specialised over time. You can have one person do one thing well to save others from having to do the job themselves.
Seen in this way though you can start to understand the limitations of GIT. Sure it is faster at merging in changes in a massive open source coding project, but the cost is that the complexity increases for each contributor. They have to learn a more complicated version control system that can easily blow up the moment they do something slightly wrong. The larger your project the larger your net cost.
A successful tool should make the user more efficient. It should make their job easier, not harder. Tools that achieve this allow people to do more than they otherwise could and be more productive.
This is why we use cars instead of horses and computers instead of an abacus.
Perhaps a future Git-like version control system will be developed that will be ideally suited for use by one person specialising in incorporating the updates from coders who can be freed up to concentrate solely on programming. Or maybe Git will eventually be developed to be intelligent enough to perform this role itself. But at the moment, it's not managing it. But this is the problem with clever tools. They are never as clever as a human being and more often than not cause more problems than they solve.
Thanks to all who have confirmed that Git's concept of operation is indeed from some Bizzaro world. I've been using version control systems for a long time, and I thought that Clearcase had pride of place for convolution to confuse the enemy (its users.) At first, I'd assumed that my own struggle to learn Git was simply evidence of my own limitations - otherwise, how could something so wildly popular be so damn hard to understand? But I now recognize this is yet another example of horrible user-interface design that results when clever programmers who don't give a damn about usability create something completely idiosyncratic, or worse, gleefully use obfuscation as a secret handshake to screen out the unworthy.
ReplyDeleteYou said it.
DeleteI do not like Git. It is too flexible and too complicated. So far, in our company, I have witnessed several serious complications and no benefits. The teams at our company would be benefiting from central, rigid source control with tight process. Despite all the Zen pics above, and pseudo-religious claptrap.
ReplyDeleteKISS principle comes to mind! But not with Git.
ReplyDeleteSome people ...admit that they are pissed using Git because it sucks out their brains more than any other VCS tool in the past. Git distracts them (not totally, but significantly more than other VCSs) from getting their “main work” done (http://scn.sap.com/people/martinkolb/blog/2015/04/02/proud-to-be-a-moron-my-journey-with-git#).
ReplyDeleteAnd this is definitely true!
We've just spent the past several months migrating the entirety of our source code, in several different programming languages and development stacks, from SVN to Git. Now, instead of allowing the developers to simply branch and merge file content as they're accustomed to doing, time and time again we have to sit down and: analyze why the merge process is doing something completely different than what we expect; figure out how to select the proper options in SourceTree and TortoiseGit to let developers stop trampling the code of other developers; analyze whether our branching and merging "mental model" is sufficient by comparing it to Git Flow, back-merges, fast-forward merges and rebasing, and merging using one of five different merge strategies; and then explaining that mental model, and the excess of command-line options that accompany it, to the developers in a way that they can understand it compared to the trivially simple "update" and "commit" operations that they want back from SVN. What a big win for us!
ReplyDeleteI use git for 6 month now, I seriously question sanity of anybody who blobs about its flexibility or some other nonsense. Talk about philosophy of source control ? Seriously ? Here is the philosophy for you , brain-dead linuxoids, - I have 2 or more versions of the same file , I JUST WANT TO MERGE IT, not stage, not fucking pull or push, aply , unaply , pop , branch , reverse, hunk, JUST FUCKING MERGE
ReplyDeleteI leave this post up as an example of what not to post. No ad-hominem (e.g. 'brain-dead linuxoids') and no cursing. This post feels like a punching bag to let out the rage. It has some relevant points: "I JUST WANT TO MERGE IT, not stage, not fucking pull or push, aply , unaply , pop , branch , reverse, hunk" which are useful to understanding the psychology of users from a UX standpoint,
Deletebut mostly it is just anger.
I support you 100% Anon! Forget about that Daniel guy :)
DeleteThis comment has been removed by a blog administrator.
ReplyDeleteYour language is abusive and threatening. I am deleting your post.
DeleteOk. I calmed down. I can control my hands now. Ok. Calmed down.
ReplyDeleteCharlatans don't have anything to sell, and keep selling you more and more complex stuff. This is typical of charlatans and untalented people. Genius is always simple. Charlatans are always complex. That is the bottom line of this whole story.
There has been a recent trend here of people posting in these comments as a discovery of "git"-trauma survivors. My guess is that the title of my posting comes back as the result of an extreme moment of frustration when someone goes to Google and types: "Why the heck is X so Y?" (where X is the object of frustration and Y is the negative quality). Mostly, these people are looking to co-commiserate with 'survivors'.
DeleteI do not share your disdain of Git, and find that these recent comments are a) echo-chamber complaining and b) short-sighted.
I do NOT think GIT is the best thing ever, but the point of my post was not to complain about its architecture, but to highlight the very real complications of real-world usage and how its difficulty arrives naturally. This Anonymous post I am responding to is silly: "genius is simple". Real-world scenarios are never simple and doing source-control in complicated situations is bound to be difficult. Almost all of software engineering is a reflection of this.
I leave all of these comments up because I think everybody can benefit from them, except the abusive posts with potty-mouth adjectives which are deleted -- they add nothing.
The main truth I gather from these angry posts is that Git is probably an overkill for many simpler situations, and many simpler organizations. From this mismatch, of putting a trendy Git into an organization and situation that may not warrant it, comes these posts.
Git is a full-fledged engine with dozens of levers and switches and an un-opaque underlying file-system. I too have to go to stackoverflow to do things outside of the normal, and I too have cursed it, but I think the many people who are posting here with their angry screeds are not realizing that being a programmer/software-engineer in a team (or even solo and with a desire to roll-back and maintain a history) requires having a rigorous set of skills around toolsets.
I know it's tough already being a programmer/software-engineer and knowing your language, its libraries and frameworks, and text-editors and unix commands, etc etc. but nobody sad it would be easy.
Simple works for simple scenarios.
This comment has been removed by a blog administrator.
ReplyDeletelike the post above, abusive language... i'll chalk it up to you having a bad day.
DeleteFor me it doesn't seem hard because it's different. It is hard because the complexity and layers are hidden. So many guides just give steps without clearly visualizing what exactly is happening in concrete terms. It's like teaching someone to write SQL queries without a way to visualize the structure of the database. Even graphical tools do a poor job of giving one access to all the different layers.
ReplyDeleteThe nuanced behavior of Git is exemplified in the many guides that cover using git pull, contradicted by the many recommendations to never use git pull and instead do a fetch+merge(which is what pull is *supposed* to do, but for many valid reasons you shouldn't use git pull). What you end up doing instead is a deterministic workflow, so we end up doing something that a computer could do for us. IMO, that's a clear loss in productivity.
That doesn't mean Git is a bad tool though. Git was created out of necessity to address certain usage scenarios that *primarily* apply to open source projects, and in turn requires these layers and complexity to accomplish certain goals. For example, being able to submit/review/accept a commit from a non-privileged user. I.e. someone without direct commit permissions. The ways to accomplish this in other VCS are by comparison fairly archaic. (Of course there are a couple other distributed tools that accomplish the same, but are also similarly complex).
So certain usage scenarios make Git or a similar distributed VCS necessary. If I'm not doing open source development, I won't use Git. When people start talking about being able to have your own local branch, most products provide features that give you similar benefits with less complexity.
For example, you have to be very careful about how update your fork from upstream to ensure your changes layer into the history correctly. When I bring new developers onto a project, I need to focus on getting them up to speed on the project itself, not the nuances of the VCS that they may not be familiar with. Not understanding all of these nuances goes beyond just a productivity issue, and can result in bad commits that either lose work or result in bad merges. I don't want that risk. I want to be able to include entry level developers on projects, and have them focus on the code, not on the VCS.
So much git-hate. I can understand.
ReplyDeleteJust use Mercurial instead. It's get all the power of git without the stupid command-line interface and rubbish documentation. The Mercurial devs actually care about making their tool easy for newcomers. See hginit.com
This comment has been removed by the author.
ReplyDeleteAs someone who is thinking about transitioning from SVN to GIT, compared to SVN I find GIT not difficult but inefficient in terms of steps a programmer needs to make in order to complete a simple task.
ReplyDeleteHere's a drawing comparing the two: https://goo.gl/GLDGFZ
I do understand the benefits of such a VCS system for large or distributed teams and open-source projects, since it protects the central repository from uncontrolled changes.
However I don't think it's well suited for small teams (especially if you're working alone). In such scenarios all the pulling and pushing, needed to keep your local repo in sync with the central repo, is just extra work, which isn't adding any value to the product you're working on.
In addition don't like the idea of having a local repo, since the HDD failure means the loss of all the changes which weren't pushed to the central repo. Commiting to the central repo has the benefit of easy backup. If your dev machine dies, all your work is still stored in the repo + a backup server.
After studying a few GIT branching workflows I concluded that most of them can be implemented in SVN with almost no effort.
I'll invest some more time in exploring GIT before I make my final decision if I'll switch from SVN. For now I don't see any benefits from switching to GIT (except maybe staying in the loop with most popular tools).
P.S.
One thing I do like about GIT is the concept of rebase. I'm yet to see how this procedure handles conflicts which might emerge.
Team Foudnation Server will do everything that Git does, but it's easy to use. The only thing that's hard in TFS is creating a trunk if you accidentally put your initial commit in the root of the bound folder. But that's not really that hard to sort out.
ReplyDeleteThis comment has been removed by a blog administrator.
ReplyDeleteI believe we sa< GIT is great because we are just conformists an scared to admit the truth. It is really over-engineered. Despite offering a nice webinterface, the rest of the functionalities are complicated. I need to spend hours to make sure I am in the right branch with the project properly settled. I svn I never had to spend more than 5 minutes. With SVN I needed to read a webpage, with GIT I need to study a book. We need to evolve toward simplicity and not complexity... we have enough complexity in our projects. Plus you add teamcity, gradle, git... where is the time left for the business implementation here???
ReplyDeletefuck git, i have tto use it because of some cloudbased computing systems and i cant waste 2 day because i have already worked for 2 months for my project which can affect my life in a very good way. again, fuck github. I just want to upload a file. Not abusive, true talking.
ReplyDeletegit was created from very small apps, it was used by many people because it was free. It is terrible but SVN is not a great solution either.
ReplyDeleteI LOVE Git! Come on guys, it's not that hard... it is more powerful.
ReplyDelete1. It "lets" you write 5 commands whereas SVN only has 1 command for the same thing.
2. You can't checkout a sub-folder like SVN, you must clone the whole repo. Awesome! Who doesn't want that?
3. Multiple errors daily with Git. This is super helpful and informational. Reminds you to stash your junk, or let you know about index errors that mean nothing to the common fool.
4. No externals support. Why would anyone want to use externals? Git has Submodules!
5. I love how you can't merge a single file from another repos/branches check-in, but you can "cherry-pick" a full check-in. Keeps your history in tact!
6. "Everyone in the valley is using it." That's the most logical reason for switching technologies. Good to have co-workers that use common sense.
7. It's faster. Switched our 4.5GB repo to Git and I can tell you something... it is not. I'd even argue it is slower. We're using it wrong, we need to break our SVN repo into 50 Git repos. That’s great!
8. Less merge conflicts. Make sure your team isn't touching the same lines of code simultaneously like any other version control system.
9. If you like to read, it is good, because you must read a book to conquer Git.
10. Git is good if you're a one-man team with small repos.
11. Fought with line ending issues today because some of us use Windows and others use Linux. Git was smart enough to automatically force line ending changes on me. I know there is a solution to this; trial and error.
11. Can't wait for more Git surprises.
What I fail to understand is why I (the user) have to tell git where to push a change to.
ReplyDeleteIf I pull the source from a network repo, change a single line in a single file, why do I then require
git add .
git commit .
git push (and then here have to know details about where to push to)
I just retrieved the source from repo X, shouldn't the default behaviour be to push my changed back to that repo ?
And, what's with the '.' character ? That's also redundant. Shouldn't the default behaviour be to commit everything in the directory tree beneath my CWD.
Why git add AND git commit ? Surely the default behaviour should be to add all changes upon commit !
I have been forced to use git now for over a year, and I can't say anything about it impresses me. I'm working on one of the largest software development projects in the world right now (You'll have to trust me on that), and I am certain I would be able to do everything I need to using an svn style command set (svn branch, svn checkout, svn checkin, svn merge), instead of a git style command set which requires more commands, and a knowledge of the data model of git to be productive.
As previously stated, tools are supposed to reduce work, and hide complexity. git does neither.
Amen brother!
DeleteGit would be a good tool if only it had a command line parameter and a matching config option called "-jfd" or "--just-fucking-doit" where every time there is an error reported "this and that would be overwritten" and "there are some changes here" or "some file i don't know about might be changed" or "it is tuesday and I don't work well on tuesdays" would be ignored and action that is requested would be done without further questions. If I have to delete the whole local git directory just to get it to work again then surely it would be possible for git to just get itself to the same state.
ReplyDeleteFor sure... seems that SVN has that switch turned on by default. I seriously, get an error every time I try to do anything. Then when I go to show my colleague, it works... piece of junk.
DeleteAfter using TFS for 15 years I've been playing with Git recently and am really struggling to understand some of the concepts. Why do I have to commit to my local repo before I can do anything else? It just seems to be such an unnecessary overhead. Give me TFS any day of the week - a few buttons to interact with it and I can do anything that Git can do.
ReplyDeleteIt’s time to activate TNT drama channel usingtntdrama.com/activate. You can visit the store to add the channel. After collecting the code for activation, provide the code by visiting the portal, tntdrama.com/activate. If the channel activation is complete, pick the top channel shows to start streaming. Please reach out to our network support, if you require any help to activate the channel and fix the issues and errors.
ReplyDeleteAre you facing Brother Printer Driver Installation Problems. Don’t be panic! Our Printer Customer Service team will provide the best solution with in few minutes. You just dial our Printer Customer Care Toll-Free Number and you also visit printer customer official website.
ReplyDeleteI saw so many testimonies about Dr Itua a great HERBAL DOCTOR that can cure all kind of diseases and give you the rightful health to live a joyful life, I didn't believe it at first, but as the pain got worse and my life was at risk after visiting my therapist numerous times for combination of treatments. And no changes so I decided to take a try, I contacted him also and told him I want a cure for Vulvar cancer/ Testicular cancer and it was Stage IIIA, he gave me advice on what I must do and he delivered it to me in my state which I use according to his instruction, and today I must say I am so grateful to this man Dr Itua for curing me from Vulvar cancer/ Testicular cancer and for restoring me back to my normal health and a sound life, I am making this known to every one out there who have been living with cancers all his life or any sick person should not waste more time just contact him with his details below- WhatsApp- +2348149277967 Email drituaherbalcenter@gmail.com, believe me this man is a good man with Godly heart, this is the real secret we all have been searching for. Do not waste more time contacting him today for you to also live a sound and happy life. He cures the following disease, thyroid Cancer, Uterine cancer, Fibroid, Arthritis, Brain Tumor,Fibromyalgia, Bladder cancer, Brain cancer, HIV, Herpes, Esophageal cancer, Gallbladder cancer, Gestational trophoblastic disease, Head and neck cancer, Hodgkin lymphoma Intestinal cancer, Kidney cancer,Hpv, Lung cancer, Melanoma,Mesothelioma, Multiple myeloma,Neuroendocrine tumors Non-Hodgkin lymphoma, Oral cancer, Ovarian cancer, Sinus cancer, Hepatitis A, B/C, Skin cancer, Soft tissue sarcoma, Stroke, Lupus, Spinal cancer, Stomach cancer, Vaginal cancer,Vulvar cancer, Testicular cancer,Tach Diseases, Pancreatic Cancer, Leukemia, Liver cancer, Throat cancer, Alzheimer's disease, Chronic Diarrhea,Copd, Parkinson,Als,Adrenocortical carcinoma Infectious mononucleosis.
ReplyDeleteAmazing Information. Your post is written in an ideal manner. Thanks for sharing
ReplyDeleteHP Printer Driver Install Error 1603
HP Printer Driver Install Error Code 1603
HP Printer Install Error 1603
HP Printer Install Error Code 1603
How to Fix HP Printer Driver Install Error 1603
Nice Blog !
ReplyDeleteOur team at QuickBooks Support Phone Number makes sure to remove all the annoying issues of QuickBooks during these challenging times.
marathon og
ReplyDeleteacdc strain
pre rolled backwoods
tko extracts
mr nice guy weed
mr nice guy strain
white moon rocks
moon rocks for sale
juicy fruit strain
marathon og strain
https://g.page/buy-medical-wee-online?ad
Nice Blog !
ReplyDeleteOur team at QuickBooks Customer Service offers you the best possible service and solutions for QuickBooks issues in these trying and uncertain times.
Buy psychedelics online USA UK Australia
ReplyDeleteLSD
Liquid LSD
Buy LSD
Buy LSD online
Liquid LSD for sale
Buy LSD Liquid
DMT
Buy DMT
Buy 4-aco-DMT
Buy 5-meo-DMT
Buy DMT online
Buy DMT Vape pen
DMT for sale
Buy Ketamine Online
where to Buy Ketamine
Buy MDMA Molly
where to buy MDMA Molly ecstasy
Buy Ecstasy online
Buy Golden Teacher mushrooms
Buy Magic mushrooms
Buy Psilocybe Cubensis spores
Buy psilocybin mushrooms
Buy Ayahuasca online
Ayahuasca for sale
Buy Shrooms online
Buy psychedelic mushrooms online
Psilocybin
Buy Magic mushrooms Online
Buy Mescaline
Buy Mescaline online
Mescaline for sale
Buy ibogaine
Buy Ibogaine online
Ibogaine for sale
Buy LSD online
Glo Extracts
ReplyDeleteGlo Carts
ReplyDeleteWhat to do if my video is not uploading on Facebook?
ReplyDeleteIf you're wondering why won't my video upload to Facebook, disable the browser extensions. On your browser, click Options and choose Settings to open it. Now, inside your browser's settings, you need to click on the Extensions tab from the side menu. Lastly, identify the browser extensions that are not related to Facebook and disable them.
Also Read
how do i get a human at verizon customer service
pop.verizon.net not responding
how to make yahoo my homepage on mac
yahoo email not syncing
yahoo mail not working on iphone
Amazing and infromative post, checkout this as well:- online biology tutor
ReplyDeleteYour style is very unique compared to other people I’ve read stuff from. Thanks for posting when you have the opportunity, Guess I will just bookmark this page 토토사이트
ReplyDeleteMy brother suggested I may like this blog. He used to be totally right.
ReplyDeleteThis post actually made my day. You can not believe simply how much time I had spent for this information! Thank you! 바카라사이트
ReplyDeleteNice post. I used to be checking constantly this blog and I am impressed! Extremely useful info particularly the ultimate section 🙂 I take care of such information a lot. I was seeking this certain information for a long time. Thank you and best of luck.
social media advantages and disadvantages essay, BOOKS PDF DOWNLOAD
ReplyDeleteNice post. I used to be checking constantly this blog and I am impressed! Extremely useful info particularly the ultimate section 🙂 I take care of such information a lot. I was seeking this certain information for a long time. Thank you and best of luck.
fino partner , The Alchemist book review
If you are looking for orange county solar companies at affordable or reasonable prices. Look no further, Burge Solar Power is one of the best solar panel company in California that specialises in installing the best solar panels at residential and commercial sites. For more information, you can call us at (951) 787-9800.
ReplyDeleteSmall Assisted Living
ReplyDeleteAssisted Living Aurora
Assisted living centennial
Castle Rock assisted living
Lakewood Gardens Care Homestead
Assisted Living Lakewood
Independent Living Lakewood
Independent Living
I read your post. I appreciate your hard work and your knowledge. Keep sharing again this type of post.
ReplyDeleteAkshi Engineers is known as the leading Hot Rolling Mill Manufacturer in India. We provide complete solutions for Hot Steel Rolling Mills. We manufacture the best quality Industrial Machinery products by using advanced technologies. Get the best deals with the extensive offer of Hot Rolling Mill through a toll-free number.
buy ragdollcatkitten online
ReplyDeleteHello!,I love your writing very so much! percentage we be
ReplyDeletein contact more approximately..
You can safely browse our links for more information about our services....
https://erasolutionrbv.com/product/rohypnol-flunitrazepam-2mg/
This comment has been removed by the author.
ReplyDeleteThanks for writing this blog, You may also like the Taurus Feast: 6 Steps to Wealth
ReplyDeletestiiizypods
ReplyDeletestiiizy
https://g.page/r/CZmEQ3Rrt7bwEA0
Our service is specifically for people, who know skin care and hair care and are smart enough to put their money in the right place to get the best quality product.
ReplyDeleteThanks for writing this blog, You may also like the
ReplyDeletevaikunta ekadasi 2022,
goddess mookambika
토토사이트 Hi there, I check your blogs like every week. Your writing style is witty, keep up the good work!
ReplyDelete스포츠토토 Awesome Article! its truly enlightening and creative update us as often as possible with new updates. its was truly important.
ReplyDeleteThis is a great post. I like this topic.This site has lots of advantage.I found many interesting things from this site. It helps me in many ways.Thanks for posting this again.
ReplyDelete카지노
marijuana flowers
ReplyDeletePandit Neeraj Sharma Ji is providing Palm Reading and Face reading Astrology services that predict fate by reading the facial features of people.
ReplyDeletebuy mescalin-or-peyote online
ReplyDeletebuy mushroom-edibles online
buy Ayahuasca online
dmt-nn-dimethyltryptamine for sale
iboga for sale
ketamine for sale
krantom for sale
lsd-lysergic-acid-diethylamide
psylocybins-magic-mushrooms
https://hippiestore.org/
Airtel Tower Office - Airtel tower installation and complain
ReplyDeleteAirtel tower agreement letter & Airtel tower approval letter
Airtel tower installation customer care number & contact no
Submit Airtel tower complaint online & get solved in 24hours
Registration open for Airtel mobile tower installation 2022
Airtel tower head office contact number and helpline number
Documents require for Airtel mobile tower installation
Airtel tower installation process and details step by step
Favorable site, where did u create the info on this uploading? I have checked out a few of the short articles on your web site now, and I actually like your style. Many thanks a million and please keep up the efficient job.
ReplyDeleteArchives
eprimefeed.com
Latest News
Economy
Politics
Tech
Sports
Movies
Fashion
Rahu in Astrology represents materialism, mischief, fear, dissatisfaction, obsession and confusion.
ReplyDeleteKetu in Astrology represents the spiritual process of evolution.
ReplyDeleteSun in 12 Houses in Astrology may trigger the character of seclusion.
ReplyDeleteRahu in Different Houses makes the native fight or argue with his family and relative.
ReplyDeleteRahu in 12 Houses in Astrology is not a very good sign for expenses and finance related stuff.
ReplyDeleteKetu in Different Houses tends to be renowned, wealthy and successful in his life.
ReplyDeleteMoon in Astrology determine survival instincts, defense mechanisms and even eating habits.
ReplyDeleteVenus in Astrology is associated with the principles of harmony.
ReplyDeleteMars in Astrology represents our source of energy and is also important in Hinduism.
ReplyDeleteJupiter in Astrology is associated with the principles of growth, expansion.
ReplyDeleteSaturn in Astrology is often called the god of karma or justice.
ReplyDeleteQuiest impressive looking forward for more intrestings blogs like this.
ReplyDeleteQuiet a great site u have developed well done
ReplyDeleteGreat job keep it up
ReplyDeleteGood very good work.
ReplyDeleteThank you almost cleared all of my doubts.
ReplyDeleteSuperbb!!!
ReplyDeleteGood well done.
ReplyDeleteBrilliant idea will try it once.
ReplyDeleteAwesome i would say it is just the poster attracts so much.
ReplyDeleteGreat work.
ReplyDeleteHey i just went through your post its awesome keep up the great work.
ReplyDeleteGood job.
ReplyDeletehlakeland pressure washing [...]below you will come across the link to some web-sites that we consider it is best to…ttps://vidhyamiLord of 8th House in 1st Housetra.com/lord-of-8th-house-in-1st-house/
ReplyDeleteLord of 8th Holakeland pressure washing [...]below you will come across the link to some web-sites that we consider it is best to…use in 2nd House
ReplyDeleteLord of In Vedic Astrology, Jupiter planet is said to be highly spiritual. … So, when Jupiter is in the first house, the native will be a very kind and compassionate person with a positive outlook and good intentions. The life of the native of Jupiter in 1st house is blessed with good luck and favourable fortune8th House in 5th House
ReplyDeleteLord of 8th House in 5th House In Vedic Astrology, Jupiter planet is said to be highly spiritual. … So, when Jupiter is in the first house, the native will be a very kind and compassionate person with a positive outlook and good intentions. The life of the native of Jupiter in 1st house is blessed with good luck and favourable fortune
ReplyDeleteLord of 8th House in 9th House Hi there! This post could not be written much better! Reading through this article reminds me of my previous roommate! He continually kept preaching about this. I most certainly will send this article to him. Pretty sure he will have a great read. I appreciate you for sharing!
ReplyDeleteLord of 8th House in 1 Hi there! This post could not be written much better! Reading through this article reminds me of my previous roommate! He continually kept preaching about this. I most certainly will send this article to him. Pretty sure he will have a great read. I appreciate you for sharing!0th House
ReplyDeleteLord of 8th House in 11th House wish to start any project that’s meant to bring them success when it comes to matters of this House. They have a lot of energy and can go through a lot of trouble because they’re all the time looking into the future.
ReplyDeleteLord of wish to start any project that’s meant to bring them success when it comes to matters of this House. They have a lot of energy and can go through a lot of trouble because they’re all the time looking into the future.8th House in 12th House
ReplyDeleteLord of thc vape juice ship to qatar [...]very few sites that transpire to become detailed beneath, from our point of view…9th House in 1st House
ReplyDeleteLord of 9th Housethc vape juice ship to qatar [...]very few sites that transpire to become detailed beneath, from our point of view… in 2nd House
ReplyDeleteLord of 9th House just beneath, are several totally not connected web pages to ours, even so, they're surely really worth going over[...]in 3rd House
ReplyDeleteLord ofjust beneath, are several totally not connected web pages to ours, even so, they're surely really worth going over[...] 9th House in 4th House
ReplyDeleteLord oI know this if off subject matter but I’m searching into beginning my very own weblog and was curious…f 9th House in 5th House
ReplyDeleteLord ofI know this if off subject matter but I’m searching into beginning my very own weblog and was curious… 9th House in 6th House
ReplyDeleteLord of 9tHowdy there! Do you know if they make any plugins to support with Research Motor Optimization? I’m trying to…h House in 7th House
ReplyDeleteLord of 9th Howdy there! Do you know if they make any plugins to support with Research Motor Optimization? I’m trying to…House in 8th House
ReplyDeleteLord of My developer is attempting to persuade me to move to .web from PHP. I have constantly disliked the thought…9th House in 11th House
ReplyDeleteLord of 9th House in 12th HouMy developer is attempting to persuade me to move to .web from PHP. I have constantly disliked the thought…se
ReplyDeleteLordbelow are some links to internet pages that we url to because we truly feel they’re really well worth…of 10th House in 1st House
ReplyDeleteLord of 10th Housbelow are some links to internet pages that we url to because we truly feel they’re really well worth…e in 2nd House
ReplyDeleteLord lakeland pressure washing [...]below you will come across the link to some web-sites that we consider it is best to…of 10th House in 3rd House
ReplyDeletelakeland pressure washing [...]below you will come across the link to some web-sites that we consider it is best to…Lord of 10th House in 4th House
ReplyDeleteLord of 10th HoIn Vedic Astrology, Jupiter planet is said to be highly spiritual. … So, when Jupiter is in the first house, the native will be a very kind and compassionate person with a positive outlook and good intentions. The life of the native of Jupiter in 1st house is blessed with good luck and favourable fortuneuse in 5th House
ReplyDeleteLord of 10th HouseIn Vedic Astrology, Jupiter planet is said to be highly spiritual. … So, when Jupiter is in the first house, the native will be a very kind and compassionate person with a positive outlook and good intentions. The life of the native of Jupiter in 1st house is blessed with good luck and favourable fortune in 6th House
ReplyDeleteLord of 10th HouseHi there! This post could not be written much better! Reading through this article reminds me of my previous roommate! He continually kept preaching about this. I most certainly will send this article to him. Pretty sure he will have a great read. I appreciate you for sharing! in 7th House
ReplyDeleteLord of 10th HHi there! This post could not be written much better! Reading through this article reminds me of my previous roommate! He continually kept preaching about this. I most certainly will send this article to him. Pretty sure he will have a great read. I appreciate you for sharing!ouse in 8th House
ReplyDeleteLord of 10th wish to start any project that’s meant to bring them success when it comes to matters of this House. They have a lot of energy and can go through a lot of trouble because they’re all the time looking into the future.House in 10th House
ReplyDeleteLord of 10th wish to start any project that’s meant to bring them success when it comes to matters of this House. They have a lot of energy and can go through a lot of trouble because they’re all the time looking into the future.House in 11th House
ReplyDeleteLord of 10th Hothc vape juice ship to qatar [...]very few sites that transpire to become detailed beneath, from our point of view…use in 12th House
ReplyDeleteLord of 11th House in 1st House https://vidhyamitra.com/lord-of-11th-house-in-1st-house/thc vape juice ship to qatar [...]very few sites that transpire to become detailed beneath, from our point of view…
ReplyDeleteLord of 11just beneath, are several totally not connected web pages to ours, even so, they're surely really worth going over[...]th House in 3rd House
ReplyDeleteLord of 11th House in 4tjust beneath, are several totally not connected web pages to ours, even so, they're surely really worth going over[...]h House
ReplyDeleteLord of 11thI know this if off subject matter but I’m searching into beginning my very own weblog and was curious… House in 6th House
ReplyDeleteLord of 11th HouI know this if off subject matter but I’m searching into beginning my very own weblog and was curious…se in 7th House
ReplyDeleteLoHowdy there! Do you know if they make any plugins to support with Research Motor Optimization? I’m trying to…rd of 11th House in 8th House
ReplyDeleteLord of 11th House iHowdy there! Do you know if they make any plugins to support with Research Motor Optimization? I’m trying to…n 9th House
ReplyDeleteLord of 11th House My developer is attempting to persuade me to move to .web from PHP. I have constantly disliked the thought…in 10th House
ReplyDeleteLord of 11th HoMy developer is attempting to persuade me to move to .web from PHP. I have constantly disliked the thought…use in 11th House
ReplyDeleteLord ofbelow are some links to internet pages that we url to because we truly feel they’re really well worth… 12th House in 2nd House
ReplyDeleteLord of 12th Hobelow are some links to internet pages that we url to because we truly feel they’re really well worth…use in 3rd House
ReplyDeleteLord oflakeland pressure washing [...]below you will come across the link to some web-sites that we consider it is best to… 12th House in 4th House
ReplyDeleteLord lakeland pressure washing [...]below you will come across the link to some web-sites that we consider it is best to…of 12th House in 7th House
ReplyDeleteLordIn Vedic Astrology, Jupiter planet is said to be highly spiritual. … So, when Jupiter is in the first house, the native will be a very kind and compassionate person with a positive outlook and good intentions. The life of the native of Jupiter in 1st house is blessed with good luck and favourable fortune of 12th House in 8th House
ReplyDeleteLord of 1In Vedic Astrology, Jupiter planet is said to be highly spiritual. … So, when Jupiter is in the first house, the native will be a very kind and compassionate person with a positive outlook and good intentions. The life of the native of Jupiter in 1st house is blessed with good luck and favourable fortune2th House in 10th House
ReplyDeleteLord of 1st House inHi there! This post could not be written much better! Reading through this article reminds me of my previous roommate! He continually kept preaching about this. I most certainly will send this article to him. Pretty sure he will have a great read. I appreciate you for sharing! 4th House
ReplyDeleteLord oHi there! This post could not be written much better! Reading through this article reminds me of my previous roommate! He continually kept preaching about this. I most certainly will send this article to him. Pretty sure he will have a great read. I appreciate you for sharing!f 1st House in 6th House
ReplyDeleteLord of wish to start any project that’s meant to bring them success when it comes to matters of this House. They have a lot of energy and can go through a lot of trouble because they’re all the time looking into the future. 1st House in 7th House
ReplyDeleteLord of 1st wish to start any project that’s meant to bring them success when it comes to matters of this House. They have a lot of energy and can go through a lot of trouble because they’re all the time looking into the future. House in 8th House
ReplyDeleteLord of 1sthc vape juice ship to qatar [...]very few sites that transpire to become detailed beneath, from our point of view…t House in 10th House
ReplyDeleteLord of 1sthc vape juice ship to qatar [...]very few sites that transpire to become detailed beneath, from our point of view…t House in 12th House
ReplyDeleteLord of 2nd Hojust beneath, are several totally not connected web pages to ours, even so, they're surely really worth going over[...]use in 2nd House
ReplyDeleteLord of 2ndjust beneath, are several totally not connected web pages to ours, even so, they're surely really worth going over[...] House in 3rd House
ReplyDeleteI know this if off subject matter but I’m searching into beginning my very own weblog and was curious…!!@!
ReplyDeleteLord of 2nd I know this if off subject matter but I’m searching into beginning my very own weblog and was curious…House in 6th House
ReplyDeleteLord of 2nHowdy there! Do you know if they make any plugins to support with Research Motor Optimization? I’m trying to…d House in 7th House
ReplyDeleteLord of 2Howdy there! Do you know if they make any plugins to support with Research Motor Optimization? I’m trying to…nd House in 9th House
ReplyDeleteLoMy developer is attempting to persuade me to move to .web from PHP. I have constantly disliked the thought…rd of 2nd House in 10th House
ReplyDeleteLord of 2nMy developer is attempting to persuade me to move to .web from PHP. I have constantly disliked the thought…d House in 11th House
ReplyDeleteLord of 2nd below are some links to internet pages that we url to because we truly feel they’re really well worth…House in 12th House
ReplyDeleteLord below are some links to internet pages that we url to because we truly feel they’re really well worth…of 3rd House in 2nd House
ReplyDeleteLord of 3lakeland pressure washing [...]below you will come across the link to some web-sites that we consider it is best to…rd House in 4th House
ReplyDeleteLord of vlakeland pressure washing [...]below you will come across the link to some web-sites that we consider it is best to…3rd House in 5th House
ReplyDeleteLord of In Vedic Astrology, Jupiter planet is said to be highly spiritual. … So, when Jupiter is in the first house, the native will be a very kind and compassionate person with a positive outlook and good intentions. The life of the native of Jupiter in 1st house is blessed with good luck and favourable fortune3rd House in 6th House
ReplyDeleteAre you looking for Nursing Pico Project Writing Services or Nursing Pico Essay Writers UK
ReplyDelete? look no further we offer the best services at affordable rates contact us for more information.
Lord of 3In Vedic Astrology, Jupiter planet is said to be highly spiritual. … So, when Jupiter is in the first house, the native will be a very kind and compassionate person with a positive outlook and good intentions. The life of the native of Jupiter in 1st house is blessed with good luck and favourable fortunerd House in 7th House
ReplyDeleteLord of 3rd HoHi there! This post could not be written much better! Reading through this article reminds me of my previous roommate! He continually kept preaching about this. I most certainly will send this article to him. Pretty sure he will have a great read. I appreciate you for sharing!use in 8th House
ReplyDeleteLord of 3rd vHi there! This post could not be written much better! Reading through this article reminds me of my previous roommate! He continually kept preaching about this. I most certainly will send this article to him. Pretty sure he will have a great read. I appreciate you for sharing!House in 9th House
ReplyDeleteLord of 3rd wish to start any project that’s meant to bring them success when it comes to matters of this House. They have a lot of energy and can go through a lot of trouble because they’re all the time looking into the future.House in 10th House
ReplyDeleteLord o wish to start any project that’s meant to bring them success when it comes to matters of this House. They have a lot of energy and can go through a lot of trouble because they’re all the time looking into the future.f 3rd House in 11th House
ReplyDeleteLord of 3rd House in thc vape juice ship to qatar [...]very few sites that transpire to become detailed beneath, from our point of view…12th House
ReplyDeleteLord of 4th Housthc vape juice ship to qatar [...]very few sites that transpire to become detailed beneath, from our point of view…e in 1st House
ReplyDeleteLordjust beneath, are several totally not connected web pages to ours, even so, they're surely really worth going over[...] of 4th House in 2nd House
ReplyDeleteLord of 4th just beneath, are several totally not connected web pages to ours, even so, they're surely really worth going over[...]House in 3rd House
ReplyDeleteLord I know this if off subject matter but I’m searching into beginning my very own weblog and was curious…of 4th House in 4th House
ReplyDeleteLord of 4th HI know this if off subject matter but I’m searching into beginning my very own weblog and was curious…ouse in 6th House
ReplyDeleteLord of 4tHowdy there! Do you know if they make any plugins to support with Research Motor Optimization? I’m trying to…h House in 7th House
ReplyDelete