Also, Why most implementations of Crockford-base32 encoding are probably incorrect
TLDR: The term base64 encoding is an overloaded term which promotes ambiguous usage. It can mean either a place-based 64-symbol encoding of a single number, or a streaming algorithm for encoding an array of octets. In common usage, it is the latter -- the same technology and IETF RFC specification that allows us to encode arbitrary binary files and place them in USENET posts and emails.
Examining the differences between the two meanings and two implementations will teach us something about ambiguity, online/stream algorithms, and that specifications are really really very important.
|
TLDR: The Crockford-base32 encoding proposal, as written here http://www.crockford.com/wrmg/base32.html, is not as clear as it could be and lacks a canonical implementation and/or test-cases.
This lack of clarity has lead most people to interpret it as a place-based 32-symbol encoding of a single number. However, the particular wording and context of his proposal implies that the Crockford-base32 encoding was meant to adhere closer to the existing base64 and base32 octet binary encodings (including padding of binary data up to a multiple of the 5-bit space).
|
The Presence of An Ambiguity
I want to use this post as a way of clearing up a confusion that seems to exist in many people's understanding of base64 (and also crockford-base32).
Because on ambiguity exists, I am going to invent my own clarifying terminology (Place-Based Single Number Encoding versus Concatenative Iterative Encoding) to attempt to disambiguate. Along the way, we will get into the nitty gritty details of binary base64-encoding (as commonly implemented in a thousand different systems) and of the radix-placed system that most people are taught as binary, octal, decimal and hexadecimal numbers.
But before I do that, let me explain what the Crockford-base32 encoding is meant to do, for those of you who have never heard of it.
Because on ambiguity exists, I am going to invent my own clarifying terminology (Place-Based Single Number Encoding versus Concatenative Iterative Encoding) to attempt to disambiguate. Along the way, we will get into the nitty gritty details of binary base64-encoding (as commonly implemented in a thousand different systems) and of the radix-placed system that most people are taught as binary, octal, decimal and hexadecimal numbers.
But before I do that, let me explain what the Crockford-base32 encoding is meant to do, for those of you who have never heard of it.
Human Readable URLs
Producing URL shortening and youtube-like resource strings seems to be the raison d'être for the Crockford and other such encodings. Many famous web applications have something like this: a unique string of letters and numbers that when used within a URL/URI, provide a unique and identifying name for that resource. Resource examples range from videos, to shortened URLS, to collabedit pages, to flickr accounts.

With all these services, we desire to provide a unique identity to a resource whose cardinality may grow into the millions or billions. Certainly, the identity could be something as simple as an integer increasing in value (what the database guys call a sequence). The drawback with a sequence is that it provides people a way to guess resource identities. To counter this, we could generate a random number with insignificant chances of repeating (and of guessing) and encoding it in a high-radix encoding to shorten its string-length.
Let's examine two ways to do this.
|
Radix Place-Based Single Number Encoding System
This system is the easier of the two to explain, as it is covered in most high-schools, and CompSci 101. Nevertheless, we will go through it again.

We start with the number 101.
What is this number? Is it the number of dalmatians that should be brutally murdered, skinned, and fabricated into a woman's coat? Or is the cost of a 5 dollar foot long?
The answer is that it could be either. The number is the ultimate abstraction, that which your brain interprets, and the glyphs and the symbols are the permanent memory of that number on paper or on disk. But in-between, we need to apply a decoding to turn interpret the glyphs from symbols through numerals to a number. In binary, the glyph/symbol/numeral string of "101" can be interpreted as "five" -- just enough dollars to buy a Subway sandwich. In decimal, which most humans (without compsci/math background) take for granted, the string "101" is interpreted as "one hundred and one."
What is this number? Is it the number of dalmatians that should be brutally murdered, skinned, and fabricated into a woman's coat? Or is the cost of a 5 dollar foot long?
The answer is that it could be either. The number is the ultimate abstraction, that which your brain interprets, and the glyphs and the symbols are the permanent memory of that number on paper or on disk. But in-between, we need to apply a decoding to turn interpret the glyphs from symbols through numerals to a number. In binary, the glyph/symbol/numeral string of "101" can be interpreted as "five" -- just enough dollars to buy a Subway sandwich. In decimal, which most humans (without compsci/math background) take for granted, the string "101" is interpreted as "one hundred and one."


To restate, the reason that we call this a radix-10 system is because we have 10 unique symbols. However to be a base-10 system, we do not have to use these exact symbols or in this traditional order. How weird a parallel universe there must be where, due to a transposition error, our system could have been 0123465789? Fifty would be "60."
Place-Based Systems
Why are the numbers made from these symbols (of any radix) called place-based systems? The answer comes from the fact that every numeric representation is a string where the place represents a power in that radix from right to left.
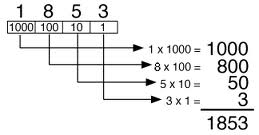
As you can see above, the simple decimal number 1853 has four places:
- farthest to the right, the ones place 100
- second to the right, the tens place 101
- third from the right, the hundreds place 102
- and fourth from the right, the thousands place 103
and the string ‘1853’ is thus a representation of a number using places to indicate powers.
A famous example of a numeral system that is not place-based is the Roman Numeral system. A Place-Based System applies not just with decimal, but with all the radix-based systems we see below.
Binary Place-Based Single Number Encoding System: 01
Standard coursework tells us of binary, a radix-2 system using (by definition) two symbols: '0' and '1'. In this base, the number 1 is '1', the number 2 is '10', the number 3 is '11', etc. This is the numeral system of computers and disks that provides the unifying clutch between voltage and symbolic logic, truth, turing machines, and computation.
 Octal Place-Based Single Number Encoding System: 01234567
If we have a base-8 system, we can only use eight symbols. Reusing our first eight symbols from the base-10 system we get: 01234567. In this base, the number seven is 7, but the number eight is 10 because we have run out of symbols. We call these octal numbers. We should call them octal numerals.
 Hexadecimal Place-Based Single Number Encoding System: 0123456789ABCDEF
And what if we have more than 10 symbols? Hexadecimal, a base 16 system, is a good example of one. We commonly choose to use some letters from the latin alphabet (whether capitalized or not) as the 6 remaining symbols. Thus our alphabet of symbols in order is : 0123456789ABCDEF. In this base, the number 15 is F, and the number 16 is 10. Most people are familiar with hexadecimal numerals usage in RGB values.
 |
Tetrasexagesimal Place-Based Single Number Encoding System
For base64, we can use the lower-case alphabet and the upper-case alphabet: abcdefghijklmonpqrstuvwxyz and ABCDEFGHIJKLMNOPQRSTUVWXYZ. But this only gives us 26*2= 52 symbols, and we need 64 symbols. The symbol alphabet of numerals 0123456789 gives us ten more for a grand total of 62 symbols. We need to add two more.
For now, let's just choose the plus symbol '+' and the slash symbol '/'. Because we can order these symbols in any order we want, how about the following ordering?
For now, let's just choose the plus symbol '+' and the slash symbol '/'. Because we can order these symbols in any order we want, how about the following ordering?
Value Encoding Value Encoding Value Encoding Value Encoding
0 A 17 R 34 i 51 z
1 B 18 S 35 j 52 0
2 C 19 T 36 k 53 1
3 D 20 U 37 l 54 2
4 E 21 V 38 m 55 3
5 F 22 W 39 n 56 4
6 G 23 X 40 o 57 5
7 H 24 Y 41 p 58 6
8 I 25 Z 42 q 59 7
9 J 26 a 43 r 60 8
10 K 27 b 44 s 61 9
11 L 28 c 45 t 62 +
12 M 29 d 46 u 63 /
13 N 30 e 47 v
14 O 31 f 48 w
15 P 32 g 49 x
16 Q 33 h 50 y
In this base, the number seven is 'H', the number 50 is 'y', the number 62 is '+', and the number 64 is 'BA'.
But now, here is the big question: Is this the same base64 encoding that was used to pass binaries and dirty images on USENET posts? Is this the base64 that most languages, browsers, and email-clients support with library functions? Is this the base64 of RFC 4648?
The answer is a big fat NO. To explain why is not the same thing, we will make a digression and consider the notions of functions and types.
But now, here is the big question: Is this the same base64 encoding that was used to pass binaries and dirty images on USENET posts? Is this the base64 that most languages, browsers, and email-clients support with library functions? Is this the base64 of RFC 4648?
The answer is a big fat NO. To explain why is not the same thing, we will make a digression and consider the notions of functions and types.
Functions and Types, Domains and Ranges
Types and functions are utterly fundamental to the art, science, and craft of programming.
One might say that types allow us to think about data, while functions allow us think about computation. Functions and types come clothed in different syntactical and run-time forms in any of your favorite language, but they are omnipresent and never to be discounted.
One might say that types allow us to think about data, while functions allow us think about computation. Functions and types come clothed in different syntactical and run-time forms in any of your favorite language, but they are omnipresent and never to be discounted.
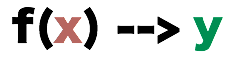
So why are we bringing them up? The answer is because we they will be helpful in explaining the difference between Place-Based Single Number Encoding and Concatenative Iterative Encoding.
Up to now, we have been describing the notion of radix and base to represent a number, a system that we called Place-Based Single Number Encoding. To help us understand this encoding, let us describe it as a function with an input and an output.
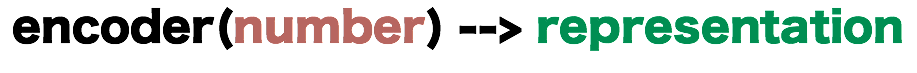
A representation is nothing more than a string of symbols in some alphabet.

Thus, the number 101 is the decimal representation of the number “one hundred and one” while 65 is its hexadecimal representation. Both 101 and 65 are strings of symbols.
This is simplistic, but really exposes the essence of what we have been doing thus far. When we wanted to convert a single number into a binary representation we implicitly knew that the Domain of our function (our input type) was that of a number, and that the Range (the return type) was that of a string of zeros and ones. We can denote this function signature like this:
This is simplistic, but really exposes the essence of what we have been doing thus far. When we wanted to convert a single number into a binary representation we implicitly knew that the Domain of our function (our input type) was that of a number, and that the Range (the return type) was that of a string of zeros and ones. We can denote this function signature like this:
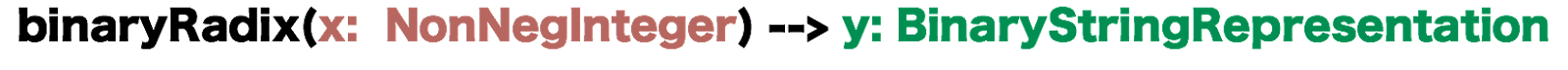
Ok. It feels like we burdened the obvious with theory. How does this help explain what email-based base64 encoding is? Well, the answer is to show the difference in their function signature, types and all.
What the base64 encoding of RFC 4648 does, and why it is different, is this:
What the base64 encoding of RFC 4648 does, and why it is different, is this:

It iteratively consumes an array of octets, transforms them into Base64 representations, and concatenates each representation into an output array.
In conclusion, we are saying one way of seeing the difference between these systems is by comparing their signatures
In conclusion, we are saying one way of seeing the difference between these systems is by comparing their signatures
Place-Based Single Number Encoding
|
Concatenative Iterative Encoding System
| |
Function
Signature
|  |  |
Does that clear it up?

Concatenative Iterative Encoding System
Yup, the term Concatenative Iterative Encoding sounds like a lot. But if we look at each word and examine its function signature, we will find it to be a description that is succinct and accurate.
Let's dissect both the term and the function signature, using the following visual of a file to motivate.

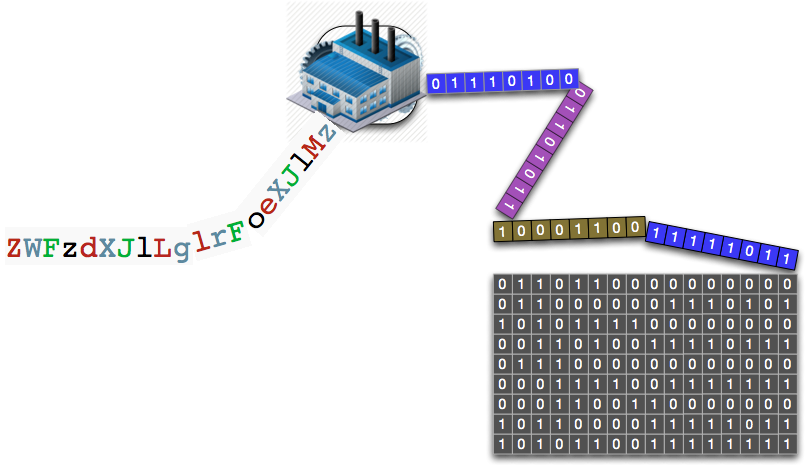
We can imagine the encoding function as a box that iteratively works its way down the tape, turning octets into base64 atoms. As the box/function moves its way down the tape, it slowly builds up the output tape by concatenating newly encoded base64 atoms. We are iteratively consuming octets from an array [OCTET] and concatenating them onto an output array of base64 representations [BASE64_REPRESENTATION].

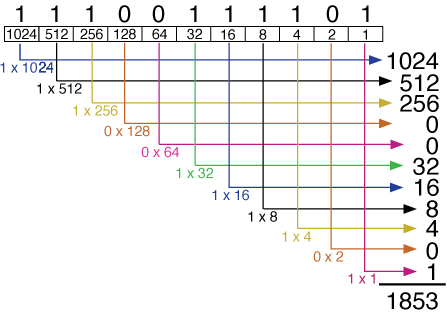
We start with a stream of octets which means that we are grouping a stream of binary bits by 8 bits each.

As you can see above, by merely choosing to put a grouping marker between every 8-bits, we can interpret this stream of 24 bits as 3 octets. Furthermore, we can choose to interpret each octet as the decimal numbers shown above, thus we see the numbers 77, 97, and 110. This example comes from the wikipedia article, showing how a text input could have been encoded, where the ASCII values for the word ‘Man’ are the input octets -- in ASCII ‘M’=77, ‘a’=97, and ‘n’=110.
So what does base64 encoding do? Does it transform the input at all? No. It merely adjusts the grouping markers. Where before we grouped by 8 bits, now we will group by 6-bits.
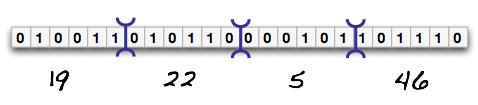
As you see above, we have reinterpreted 24-bits of data as 4 groups of 6-bits (sextets) rather than 3 groups of octets. Again, putting a decimal number for these new groups, we see the numbers 19, 22, 5, 46. But remember that base64 symbol table we had above? I will copy it down here again:
Value Encoding Value Encoding Value Encoding Value Encoding
0 A 17 R 34 i 51 z
1 B 18 S 35 j 52 0
2 C 19 T 36 k 53 1
3 D 20 U 37 l 54 2
4 E 21 V 38 m 55 3
5 F 22 W 39 n 56 4
6 G 23 X 40 o 57 5
7 H 24 Y 41 p 58 6
8 I 25 Z 42 q 59 7
9 J 26 a 43 r 60 8
10 K 27 b 44 s 61 9
11 L 28 c 45 t 62 +
12 M 29 d 46 u 63 /
13 N 30 e 47 v
14 O 31 f 48 w
15 P 32 g 49 x
16 Q 33 h 50 y
As we look at it, we can assign the number 19 to the base64 encoded numeral ‘T’, ‘W’=22, ‘F’=5, and ‘u’=46. Thus,

a text file with the ASCII contents of ‘Man’ will result in a base64 encoding of ‘TWFu’.
Summing it all up
The Concatenative Iterative Encoding System has the following signature,
which in our particular example looks like:

or equivalently

And that is it. That is what base64 encoding does. It groups a stream of binary bits (grouped in 8-bit chunks) into a stream of output 6-bit sextets. Each sextet is interpreted as a single symbol from the radix-64 alphabet, and re-emitted as the ASCII representation of that symbol.
Is it Compressions? No.
There always seems to be a major misapprehension of base64’s purpose, and one that we should try to clear up right now.
Base64 Encoding as a Concatenative Iterative Encoding System permits an arbitrary binary file to be translated into a string of text and copied in an email, or posted in a Usenet post. We have protected higher-level applications (like MIME) from arbitrary binary by choosing only letters that can exist within that application’s specification. We have compressed the string length of symbols but we have not compressed the overall data size. In fact, we have actually inflated the size of the overall data payload by re-embedding the string ‘TWFu’ using ASCII. Let us repeat the last statement: base64 does not compress the input data. In fact it inflates the size. It only compresses the length of the symbol string, by using an alphabet with more symbols. |
A Final Comparison
Place-Based Single Number Encoding
|
Concatenative Iterative Encoding System
| |
Function
Signature
| | |
Input Type
|
Single Number
|
Array of Octets
|
Output Type
|
representation of number in different radix
|
Array of Base64 representations
|
Consumption Direction
|
Right to Left
 |
Left to Right
 |
Used For
|
Representing a single number in a different radix, using a different alphabet consisting of different symbols.
|
Turning arbitrary binary into a left-to-right array of encoded characters that may be embedded and transferred within the context of an applications.
|
On the other hand base64 as a Concatenative Iterative Encoding System consumes binary data from left to right. The reason for this is that base64 encoding usually operates on files which cannot always be loaded into memory. This is why we have subtly been referring to this algorithm as a streaming algorithm -- it does not have access to the entire input, but may start generating the output with only the first three octets. The actual physical implementation of reading bits from disk means that we always have access to the most significant bits (leftmost) before the least-significant bits (rightmost) are event loaded from disk.
The Place-Based Single Number Encoding is not appropriate for encoding a file because you would
- need to load the file into memory to know its numeric representation
- the number would be HUGE
Padding is one of our hints that we are dealing with a streaming algorithm.
Finally, An Analysis of Crockford-base32 and its Implementations
The Crockford-base32 implementation has a few desirable properties that I will copy directly from the website:
The encoding scheme is required to
|
Additionally, it tries to remove accidental obscenities and ambiguous looking symbols (like 0 and O).
I needed a Crockford32 implementation for Erlang but could not find one, so I looked up various implementations in other languages to try to understand what they did. I also looked closely at the base64 implementation that comes with the Erlang runtime. It was then that I figured out that the Crockford32 implementation implies Concatenative Iterative Encoding System but that all the implementations I could find are Place-Based Single Number Encoding.
I needed a Crockford32 implementation for Erlang but could not find one, so I looked up various implementations in other languages to try to understand what they did. I also looked closely at the base64 implementation that comes with the Erlang runtime. It was then that I figured out that the Crockford32 implementation implies Concatenative Iterative Encoding System but that all the implementations I could find are Place-Based Single Number Encoding.
The Conflicting Evidence
Evidence for thinking Crockford32 was meant to be a
Place-Based Single Number Encoding
|
Evidence for thinking Crockford32 was meant to be a
Concatenative Iterative Encoding System
|
All implementations use this assumption.
|
Zero implementations use this assumption.
|
The quote from the website saying,
“This document describes a 32-symbol notation for expressing numbers in a form that can be conveniently and accurately transmitted between humans and computer systems.” Emphasis mine. |
Quotes from the page that compare it in context with other Concatenative Iterative Encoding Systems
"Base 64 encoding uses a large symbol set containing both upper and lower case letters and many special characters. It is more compact than Base 16, but it is difficult to type and difficult to pronounce.” “Base 32 seems the best balance between compactness and error resistance. Each symbol carries 5 bits.” |
Language that implies that the primary use-case for this encoding is Human consumption which means short strings.
Short strings do not require streaming algorithms, as an entire number can absolutely be loaded into memory: “Be pronounceable. Humans should be able to accurately transmit the symbols to other humans using a telephone.” |
The most damning quote of all:
“If the bit-length of the number to be encoded is not a multiple of 5 bits, then zero-extend the number to make its bit-length a multiple of 5.”
This quote is absolutely about padding enough bits to the rightmost digits.
|
Conclusion
In the end, I think this has been a nice learning experience for me, and hopefully something worth sharing. Importantly, it drives home a few points:
- most base32/16/64 encodings were designed to be streaming algorithms and operate only on octets and usually on a dataset that would not fit into memory
- the recent explosion in services that want short-URLs while having unique identities for resources have increased the need for non-streaming radix-encoding algorithms
- specifications are very important. The Crockford32 page is ambiguous, especially in comparison with the base64 specification which even includes test cases
Finally, here is an Erlang implementation I wrote for Crockford-32 as a Place-Based Single Number Encoding.
Nice write-up.
ReplyDeleteWhat a horrible theory!
ReplyDeleteYour evidence for Crockford32 being a Concatenative Iterative Encoding System is completely unconvincing.
When Crockford talks about base64, he explicit refers only to the "symbol set" it "uses". No comparison is made with the standard as a whole.
"Base 10 is well known and well accepted" is also obvious proof that this is a scheme to encode integers and not arbitrary data. There is no well-known standard for transmission of binary data in base 10, as it would be computationally very expensive. However there is no doubt that people use base 10 all the time to encode integers!
Your interpretation of "zero extension" to mean padding the rightmost digits is also flawed. It's the unsigned counterpart to "sign extension", and it is extremely common: for example the x86 has a dedicated MOVZX instruction to perform Zero eXtension (by padding the leftmost digits).
If you want to contradict the clear and unambiguous statement that "This document describes a 32-symbol notation for expressing numbers", you should have better evidence than that. You're the only one to think that the standard is ambiguous in that regard. But I do agree that test vectors would be nice, and I would add that endianness should have been explicitly mentioned.
A "horrible theory", like my use of the word "incorrect" might be a bit harsh, but I do appreciate your passion.
DeleteI don't advance my interpretation with 100% certainty, and I feel like I was honest enough to present a table showing evidence for both sides. The ambiguity was the frustrating part, not any belief that implementations were "incorrect".
Your point about base10 is well-taken and does give me pause.
However, I want to push back about the padding argument. Since neither left nor right padding was mentioned, the ambiguity remained. I reasoned thusly:
Why would you need to pad non 5-bit multiples to the left?
This argument is key. The quote from the page is this: “If the bit-length of the number to be encoded is not a multiple of 5 bits, then zero-extend the number to make its bit-length a multiple of 5.”
As an example, take a 32-bit (4-octet) number, like 01100001011000010110000101100001 (which in decimal, is 1633771873). This is NOT a multiple of 5-bits.
Why, just because it is not a multiple of 5-bits, should I zero-pad it to the left with 3-more bits, or 8-more bits?
Left-based zero padding, DOES NOT CHANGE THE VALUE OF THE NMUBER at all.
crockford32NumberEncoding(01100001011000010110000101100001) --> "1GP2RB1"
crockford32NumberEncoding(0000000001100001011000010110000101100001) --> "1GP2RB1"
The statement from the page,
“If the bit-length of the number to be encoded is not a multiple of 5 bits, then zero-extend the number to make its bit-length a multiple of 5”
is quite a strong statement of the form: "If then ". I can't believe it was made with the knowledge that the action has no impact whatsoever, otherwise it is completely irrelevant and can and should be removed.
If padding to the left does not matter, then all that remains is padding to the right, which DOES matter. It was actually this sentence in the specification that gave me pause as I was familiar with how base64 encoding right-pads and inserts "==" in the output string as indication of the padding.
If we right-pad, we get
crockford32NumberEncoding(0110000101100001011000010110000100000000) --> "C5GP2R80"
and "C5GP2R80" != "1GP2RB1"
I don't know what Douglas Crockford meant the specification to REALLY be. I would love him to find this page and answer. Most people interpreted it as a base32-radix encoding with a single number. Me too.
Sorry for the strong words, I saw it on Hacker News where the title was "Why most Crockford32 Implementations are Wrong". The hubris of this statement made me overlook the more tentative wording of the post.
Delete"Left-based zero padding, DOES NOT CHANGE THE VALUE OF THE NMUBER at all."
And it's exactly the reason why it's chosen! Padding the shortest binary representation of a number to the left introduces no ambiguities, since the first digit is always a 1 (for non-zero numbers), whereas padding to the right would make decoding ambiguous ("10000" could correspond to 1 or 10 or 100...).
Of course padding is only necessary if you start from a binary representation of the number and want to transform it into a base 32 representation. You don't need it if you compute the base 32 representation from scratch:
1100001011000010110000101100001 (base 2)
= 1GP2RB1 (base 32)
= 00001 10000 10110 00010 11000 01011 00001 (base 2)
where you see that zero-extension to a multiple of 5 bits has happened naturally. I'm guessing that's why you find this mention of padding unnecessary: it's just that it was written with binary representation as a starting point.
And that kind of padding is completely different from base64's padding with "=" symbols, which aims to let you concatenate different blocks of base64-encoded data. It doesn't make sense to concatenate numbers, that's why Crockford32 goes as far as using "=" for a completely different purpose. If it was an alternative to base64, it would have been wise to at least keep the option of base64-style padding open!
Respectfully, I am not understanding you point here.
DeleteIt seems you are agreeing that padding to the left does not change the number (and very importantly here, we are talking about bit representations of integers in an unsigned schema, since nowhere have we opened the can of worms that is 1's-complement or 2's complement for negative numbers).
I completely agree with your statement, "Padding the shortest binary representation of a number to the left [with zeros] introduces no ambiguities" as that was exactly my point, but I take it further and say, "zero padding to the left introduces no ambiguities, but there were no ambiguities to be introduced in the first place".
You gave me the number: 1100001011000010110000101100001
It is 31 digits long. Its decimal representation is 1633771873. I feel no ambiguity in understanding what number it represents -- and yet it is not a multiple of 5-bits. Why do I need to pad four extra zeros to the left (35 bits now), to make it a multiple of 5? Why is Crockford-32 telling me I should zero-pad?
As such, I am still left with this question about the Crockford 32 specification:
---------------------------------
If left-padding was implied, why does the sentence,
“If the bit-length of the number to be encoded is not a multiple of 5 bits, then zero-extend the number to make its bit-length a multiple of 5”
have to exist at all? What does it add to the discussion regarding implementation?
---------------------------------
If it adds nothing under a left-zero-padding assumption, then it is irrelevant and should be removed. Would you agree with that?
But since it is present, I take its very existence to mean something. Especially since in _most_ base encodings, the implementation of padding is meant to line up the N-bit-space with the 8-bit (octet) unit of data storage in all files, and is always right-padded.
I believe that the very presence of this sentence is probitive of a "Concatenative Iterative Encoding" interpretation.
I would prefer the specification be re-issued with these ambiguities removed.
I see no reason to not have both: 1) a specification for encoding a single number, and 2) a specification for a data encoding that operates on octets and must be zero-padded to the right if the final bit count is not a multiple of 5 and 8 -- like regular base64, base32, or the Zooko-base32 encoding.
Likewise, it would be neat if people acknowledged the differences when they were teaching base64 as ONLY "Concatenative Iterative Encoding". As an example of that is this blog post
http://code.tutsplus.com/tutorials/base-what-a-practical-introduction-to-base-encoding--net-27590
where the author starts with a "Place-Based Single Number Encoding" interpretation until he gets to base32 and base64 at which point he switches to a "Concatenative Iterative Encoding" interpretation.
"You gave me the number: 1100001011000010110000101100001
DeleteIt is 31 digits long. Its decimal representation is 1633771873. I feel no ambiguity in understanding what number it represents -- and yet it is not a multiple of 5-bits. Why do I need to pad four extra zeros to the left (35 bits now), to make it a multiple of 5? Why is Crockford-32 telling me I should zero-pad?"
Your process in obtaining 1633771873 was the following:
representation in base 2 "1100001011000010110000101100001"
->
abstract mathematical integer
->
representation in base 10 "1633771873"
You're using algebra (multiplications, divisions) to convert back and forth to the abstract mathematical integer. It's the only way to do it, because 10 and 2 are not powers of some common radix, that is, log 10 / log 2 is irrational.
But, if you want to convert it to base 16 or 32, there is another way:
representation in base 2 "1100001011000010110000101100001"
->
padded representation in base 2 "00001 10000 10110 00010 11000 01011 00001" (the spaces are here just for clarity)
->
representation in base 32 "1GP2RB1"
Here, each step is simple, local, and involves no algebra: the first step pads to a multiple of 5 bits, and the second step is just a lookup of the symbol corresponding to each group of 5 binary digits. The reason you need to pad to a multiple of 5 bits is simply that you couldn't do the lookup if you couldn't split the binary string into groups of exactly 5 bits!
I can't read minds, but I think Crockford simply wrote the specification with the mental model of the second process. He just didn't write down the lookup step.
This comment has been removed by a blog administrator.
ReplyDeleteGreat article.
ReplyDeleteI find it shocking that all of these library authors would find it intuitive for hex (base16) and base encoders to have an API like encode([octets]) but for base32 a much more limiting encode(number) would make more sense.
ReplyDeleteI guess this leaves us with fundamentally two different Crockford base32 standards, streaming and numeric? Maybe someone feels compelled to advertise a clarified spec with both of these as sub-codecs. Crockford fixing his web page would be nice but maybe enough harm has been done that a better way would be to accept that both are reasonable and already implemented viewpoints. We might be better off just documenting them both instead of figuring out which one is "correct".
Thanks for the article! At least that cleared up why my work-in-progress (stream) implementation doesn't match the output of some other libraries for even a single low number/byte.
Unfortunately, the Dish anywhere is not available as a stand-alone app on Roku where. But you can screen share dish anywhere on roku. How to do this? It is simple! Download the app on your iPhone device and install it. Enable the screen sharing option on iPhone and Roku devices and connect them. Moreover, you must launch the app and start the streaming process. If you want to know the detailed steps regarding watching Dish anywhere programs on Roku, you can navigate our sites and read the articles about it. (Connecting Roku on Apple TV is must). Call +1-805-221-0330 for any doubts
ReplyDeleteAOL is one of the best online email service platforms. Which also has amazing features with more security reasons. Sometimes, when your AOL Mail Not Working on MacBook Pro, don't worry, you can consult our expert and easily resolve your issues within a few minutes. And moreover, you can dial our toll-free number and talk to our technical expertise to solve your problem. You can also visit our website.
ReplyDelete
ReplyDeleteNice Blog! I never read this kind of content!
Akshi Engineers has the resources to Gear Boxes Manufacturer in India at affordable and reasonable prices. To learn more contact us to discuss how we can fulfill your requirment of Gear Boxes as soon as doable. Our Company offering all the equipment realtes to rolling mill industry with 100% satisfaction or quality at best prices in india and other countries. For more information cantact us or visit our website.
This is very interesting, thanks for the amazing blog.
ReplyDeleteIf you have any issues related to QuickBooks like Change QuickBooks Password, Download QuickBooks File Doctor, and QuickBooks Error Code then click here
Download QuickBooks File Doctor
Download QuickBooks File Doctor tool
Network Issues With Download QuickBooks File Doctor
Company File And Network Issues With Download QuickBooks File Doctor
QuickBooks File Doctor tool
QuickBooks Online Error Code 101
QuickBooks Online Banking Error 101
QuickBooks Error Code 101
QuickBooks Banking Error 101
QuickBooks Online Banking Error Code 101
to resolve all the issues related QuickBooks.
Nice Post. I appreciate your hard work and your skills. Thank you for sharing.
ReplyDeleteAkshi Engineers Pvt. Ltd. Company manufacture Hot Rolling Mill Manufacturer in India for flat products like mill stand, gear boxes, shears and pinch roll etc. The Hot Rolling Mills are normally of 2Hi or 5Hi configuration depending on the type of product being rolled. The 2Hi Hot Rolling Mills are used for materials like Aluminum, Copper, Brass and other softer metals whereas the 5Hi Hot Rolling Mills are used for harder metals like Stainless Steel, Alloy Steel etc. Get Best deal by calling us at +91-98106-62353 or you can also email at sales@akshigroup.com
Goassignmenthelp is a team of leading professional writers for Assignment Help to students all around the world. Contact us persuasive essay today for the Best Essay Writing Services at a very affordable price. Hire native seasoned experts essay typer at very affordable prices. We are the most reliable programming assignment help assignment helpers.
ReplyDeleteThis is really helpful post, very informative there is no doubt about it. I found this one pretty fascinating. 경마사이트
ReplyDeleteYou always comes with great stuff for your user. Thanks for being user friendly :) and Keep posting such great stuff 사설토토
ReplyDeleteIf you are looking for the best CA foundation pendrive classes offered by experienced faculties coming from different fields of expertise.
ReplyDeleteThanks for sharing a great article. You are providing wonderful information, it is very useful to us. Keep posting like this informative articles.
ReplyDeleteCNC Roll Turning Lathe Machine is the best replacement solution of Hot Rolling Mill manufacturers, suppliers, and exporters in India. CNC roll turning lathes are available in many models, which drive enormous reliability improvements, reduce work requirements, removes manual mistakes, and reduces the space used to rotate in rolling work.
Online Terpercaya di asia hadir untuk anda semua dengan permainan permainan menarik dan bonus menarik untuk anda semua
ReplyDeleteBonus yang diberikan NagaQQ :
* Bonus rollingan 0.5%,setiap senin di bagikannya
* Bonus Refferal 10% + 10%,seumur hidup
* Bonus Jackpot, yang dapat anda dapatkan dengan mudah
* Minimal Depo 15.000
* Minimal WD 20.000
* Deposit via Pulsa TELKOMSEL
* 6 JENIS BANK ( BCA , BNI, BRI , MANDIRI , CIMB , DANAMON )
Memegang Gelar atau title sebagai AGEN POKER ONLINE Terbaik di masanya
Games Yang di Hadirkan NagaQQ :
* Poker Online
* BandarQ
* Domino99
* Bandar Poker
* Bandar66
* Sakong
* Capsa Susun
* AduQ
* Perang Bacarrat
* Perang Dadu (New Game)
Info Lebih lanjut Kunjungi :
Website : NAGAQQ
Facebook : NagaQQ official
WHATSAPP : +855977509035
Line : Cs_nagaQQ
TELEGRAM :+855967014811
BACA JUGA BLOGSPORT KAMI YANG LAIN:
Winner NagaQQ
Daftar NagaQQ
nagaqq
Quickbooks helps you in tracking all the businesses operations very accurately and efficiently for all small and medium sized businesses. Sometimes you may not be able to run the operations correctly due to many reasons. You need to resolve these issues as quickly as possible to avoid any losses in your work. Quickbooks may encounter some bug issues and this can result in occurrence of issue- QuickBooks unable to complete the operation and need to restart Error.
ReplyDeleteQuickbooks helps all small and medium sized businesses in their accounting tasks and also helps in maintaining the company files and records etc. However at times, you may face an issue where Quickbooks is unable to verify Financial institution Error. And, this happens when Bank ID is not properly entered or if the program does not recognize the ID code.
ReplyDeletePlease send content elimination requests to the unique source of the video. We just embed the movies from larger sites like Porn Best Website If you remove your video from its unique supply it is going to be removed from our web site Daily Porn Update
ReplyDeleteI’m happy to provide the best review rating your blog post with the title “How to activate Fx Networks using the portal, fxnetworks activate Roku. You have explained the activation process clearly. Let me share the post with users who do not know how to activate Fx Networks channel
ReplyDeletehttps://www.prakse.lv/enterprise/profile/7323/igpinstitute
ReplyDeletehttps://investimonials.com/users/sunilsharmaigp@gmail.com.aspx
https://findery.com/sunilsharma1
https://www.bizinfe.com/Igpinstitute
https://www.walkscore.com/people/296500010919
https://www.spoke.com/lists/604b687a38d37e3dbd01de1a
https://indiabusinesstoday.in/users/detail/sunilsharma-10857
http://www.thedesignportal.org/business/igp-institute/
Excellent article and great share
ReplyDeleteAfter reading your article with the title “How to execute NatGeoTv/Activate steps, I became a big admirer. You have a great job Let me share the post with streamers who do not know how to activate Nat geo channel
Excellent and informative article. I’m impressed after reading I felt hard to activate Roku. After reading your blog post, I could activate the device easily using the portal,
ReplyDeleteRoku Com Link.
Wonderful article! 바카라사이트 We are linking to this particularly great content on our
ReplyDeletewebsite. Keep up the great writing.
카지노사이트윈 I have been browsing online more than 3 hours lately, but I by no means found any fascinating article like yours. It is pretty price sufficient for me. In my view, if all webmasters and bloggers made excellent content as you probably did, the web might be much more helpful than ever before.
ReplyDelete토토사이트 We stumbled over here from a different web address and thought I might as well check things out. I like what I see so now i am following you. Look forward to looking into your web page repeatedly.
ReplyDelete토토 Keep up the superb work, I read few blog posts on this website
ReplyDeleteand I conceive that your site is really interesting and contains lots
of wonderful info.
https://www.reverbnation.com/igpinstitute
ReplyDeletehttps://www.atlasobscura.com/users/51cb9625-0ff3-4104-b6ee-44880cc5a4a9
https://list.ly/sunil-sharma-5/lists
https://www.tuugo.us/userProfile/igpinstitute/2366694
https://transtats.bts.gov/exit.asp?url=https://shop.igpinstitute.org/product/CA-Inter-CMA
https://transtats.bts.gov/exit.asp?url=https://shop.igpinstitute.org/
https://www.magcloud.com/user/igpinstitute
https://sunilsharma.dreamwidth.org/profile
https://tapas.io/sunilsharmaigp
https://ioby.org/users/sunilsharmaigp446145
https://www.flicks.co.nz/member/sunilsharmaigp9631/
https://speakerdeck.com/sunilsharma
https://startupmatcher.com/p/igpinstitute
http://forums.qrecall.com/user/edit/148334.page
https://www.ultimate-guitar.com/u/sunilsharmaigp
https://www.flipcart.link/user/sunilsharma
ReplyDeletehttp://org.domhold.com/shop.igpinstitute.org
https://coastalncfishing.com/community/profile/sunilsharma/
https://www.skillshare.com/profile/Sunil-Sharma/317465937
https://social.technet.microsoft.com/Profile/Igp%20institute
https://www.max2play.com/en/forums/users/igpinstitute/
http://ruspioner.ru/profile/view/45101
https://www.nj24.pl/users/sunilsharma
https://pinshape.com/users/1285371-sunil-sharma#designs-tab-open
https://www.manaaki.io/forums/users/igpinstitute/
https://www.ugazdinky.sk/forums/users/Igpinstitute
https://www.snupps.com/Igpinstitute
https://www.bitsdujour.com/profiles/dTNOCg
https://www.corporatelivewire.com/profile.html?id=71baf09a74dc618d9b0679309e9bc32a44844cbc
If you don't know how to download driver and software using 123.hp.com/setup, read this article titled "HP Printer Setup." The content of the blog is outstanding. Spend your leisure time reading the page if you're ready to begin the Printer setup. If you're a first-time HP printer user, I recommend reading the blog for more information on HP printers. Also, the article was clear, and you may set up your printer on your own.
ReplyDeletehttps://www.codingame.com/profile/1da09614d8264865c054387917c0bec81563244
ReplyDeletehttps://linustechtips.com/profile/836853-igpinstitute/
https://www.glistatigenerali.com/users/sunilsharma/
https://www.codemade.io/user/sunilsharma/
https://naijamp3s.com/profile/rahulsharma1
The blog written is extremely impressive, with a great topic. However, a bit more research could have strengthened it even further. LiveWebTutors is one of the reputed Dissertation Editing Services provider in the UK. The most effective and informative contents for the students.
ReplyDeleteToday I was surfing on the internet & found this article I read it & it is really amazing articles on the internet on this topic thanks for sharing such an amazing article. Are you looking for Essay Writing Help ? so contact us soon.
ReplyDeletehttps://actionnetwork.org/users/aman-sharma-3/profile
ReplyDeletehttps://theomnibuzz.com/members/amansharma/profile/classic/
https://www.sporcle.com/user/amansharmatravel/
https://rabbitroom.com/members/amansharmatravel/
https://www.pixiv.net/en/users/68621878
Best blog Ever! A big thumbs up for your authentic information on this blog. I will come back for more. How to Buy Data on Airtel 200 for 1gb
ReplyDeleteIt's a very nice and informative article, Thank you for sharing this topic. N-Power Login Website
ReplyDeleteYou made some good points there. I searched for the subject matter and found most individuals will go along with your blog. Congratulations! strong love message for her
ReplyDelete카지노사이트 Interesting topic for a blog. I have been searching the Internet for fun and came upon your website. Fabulous post. Thanks a ton for sharing your knowledge! It is great to see that some people still put in an effort into managing their websites. I’ll be sure to check back again real soon.
ReplyDelete카지노사이트 Wonderful and useful submit. I found this much helpful
ReplyDelete토토사이트 You did cheerfully empower me because of the ideas you have posted.
ReplyDeleteBeautiful blog with valid info. UBA Graduate Trainee Recruitment 2021
ReplyDeleteAre you ready to start 123.hp.com/setup? Let me suggest an article to read.
ReplyDeleteRead the post a few days back. I could find 123.hp.com/setup steps,
software installation procedure, troubleshooting guide to fix setup issues. It will be useful if you can suggest the latest Printer models available in the market today.
Howdy, that is striking material. I truly like the subject. Would you have the choice to uncover to me something about it ... I'd love to learn. The water damage restoration company. Best offers 80% off. Best Price available in this platform.
ReplyDeleteAbsolutely this blog is unique and informative. You are a good blog creator and writer. You readily explained every topic! Looking forward to reading more posts from your blog…this site is equally good, just check it out...check my post on overwatch ranks
ReplyDeleteThanks for the interesting knowledge and ideas given to your viewers. I enjoyed coming around this blog and I am looking forward to read more of your article. nmu post utme past question
ReplyDeleteAmazing write-up and great share
ReplyDeleteI’m impressed and have no other words to comment on your blog. I could understand the Roku.com/link activation procedure after reading your blog. Kindly post the features of the top Roku device models available in the market today. My review rating your post would be 100 Starz
Keep posting more creative blogs. I can share the post with users who do not know how to activate Roku using Roku.com/link
https://openlyvoluntary.com/Lets-think-forum/profile/sunilsharma/
ReplyDeletehttps://wefight.gouette.com/community/profile/sunilsharma/
https://www.freerunmom.com/forum/profile/romitsingh/
https://winter-modular.com/community/profile/sunilsharma/
https://venus.coolforum.info/profile.php?mode=viewprofile&u=1065
To activate the Travel channel, here we explain the channel activation steps. Select your device and access the device app store to add Travel channel. Launch the channel app. Then proceed with the settings to collect the Travel channel activation code. Enter the code by visiting the portal, Travelchannel.com/activate to complete the channel activation. If you require any help to activate the channel, dial the toll-free number provided on our portal
ReplyDeleteyou have explain streaming algorithm for encoding an array of octets and based 64 encoding in very simple ways. Look in this article
ReplyDeletewww quickbooks com support update html error 1603 I adopt a very simple and intrective way so that we can provide the best solution of the error-1603
Fabiflu Tablet is an anti-viral medicine used to treat mild to moderate COVID-19 disease under emergency conditions. This medicine full name is fabiflu 400 mg tablet
ReplyDeleteThe contents of this blog are always very interesting, educative and informative, I must commend you for the good work you are doing here while I urge you to keep it up romantic good morning message for her to fall in love
ReplyDeleteAwesome post. It really shows your immense knowledge and research on this topic. Please keep sharing. Also, Check death quotes
ReplyDeleteAt HAND IN HAND REMODEL AND REPAIR LLC, we have helped thousands of victims of flood and storm damage throughout the state of Washington and the nation. Our team is equipped to restore properties of all sizes and all degrees of damage. When you contact us, we respond quickly and will arrive on-site within 30 minutes or less. We get right to work, employing our proven Flood Damage Restoration process so that you can get back to enjoying your home or running your business.
ReplyDeletequickbooks file doctor is a tool for those who are in accounts field quickbooks file doctor download
ReplyDeleteAs I do not know how to complete 123-hp-com-dj3755 setup and resolve setup issues, read your blog post titled, How to begin 123-hp-com-dj3755 setup. You have explained the setup process clearly. I like the blog format as well. Let me share the blog on my social media profile
ReplyDeleteThanks for sharing. I found a lot of interesting information here. A really good post, very thankful and hopeful that you will write many more posts like this one. You may want to see prayer for the dead islam
ReplyDeleteOutstanding Information. Thanks for sharing with us. Keep sharing again.
ReplyDeleteAkshi Engineers has a outstanding Mill Stand Solution available. We exportes, manufacturers and supplies Mill Stand & TMT Bar for Rolling Mill. If you have need mill stand for Rolling Mill, pls contact us via a toll-free number or visit the website.
Excellent Post. I appreciate your knowledge and your hard work. Thanks for sharing with us.
ReplyDeleteIf you are looking for the Best Personal Loan Provider In India. do not go anywhere. Easy Loan Mart is one of the leading loan service providers with low-interest rates. We provide loan services based on your unique circumstances. We have an online personal loan facility, you can also apply for a personal loan online. To get an instant approval for a low EMI personal loan, visit our website.
I have just read this blog and I’ll surely come back for more posts, and also this article gives the light in which we can observe the reality of the topic. Thanks for this nice article! Now read this too...happy doctors day gif
ReplyDeleteI just want to say I’m new to blogs and certainly savored this blog site. Very likely I’m planning to bookmark your blog . You amazingly have fantastic articles. Thanks for sharing your blog.야동
ReplyDeleteVery good article! We are linking to this particularly great content on our site. Keep up the great writing. Pretty valuable material, overall I consider this is worth a bookmark, thanks 대딸방
ReplyDelete"It has a good meaning. If you always live positively, someday good things will happen. Let’s believe in the power of positivity. Have a nice day.횟수 무제한 출장
ReplyDeleteNice post. I learn something totally new and challenging on sites I stumble upon every day. 타이마사지
ReplyDeleteRecently, I have started to read a lot of unique articles on different sites, and I am enjoying that a lot. Although, I must tell you that I still like the articles here a lot. They are also unique in their own way. 먹튀검증업체
ReplyDelete
ReplyDeleteI amazed with the research you made to make this actual submit incredible.
Great activity!
Have a look at my homepage; 사설경마
Hello, I read the post well. 안전놀이터추천 It's a really interesting topic and it has helped me a lot. In fact, I also run a website with similar content to your posting. Please visit once
ReplyDeleteIt as really a great and helpful piece of info. I am glad that you shared this helpful info with us. Please keep us up to date like this. Thank you for sharing. 토토
ReplyDelete토토사이트 I really enjoy the blog.Really looking forward to read more. Really Great.
ReplyDeleteGreetings ! Very useful advice in this particular article! Thanks a lot for sharing! Feel free to visit my site Stem Subjects List
ReplyDeleteQuality articles is the secret to attract
ReplyDeletethe visitors to go to see the site, that’s what this website is providing. 스포츠토토 하는법
스포츠토토 Hurrah! In the end I got a weblog from where
ReplyDeleteI be able to actually take helpful data concerning my study
and knowledge.
카지노사이트추천 See the website and the information is very interesting, good work!Thank you for providing information from your website. On of the good website in search results.
ReplyDeleteWhen you find out your child is lying to you, ask him: Did this really happen or did you wish it happened?
ReplyDeleteGive your child an extra consequence مشکلات زمان خواب در نوزادان as a result of the lie he told. This is done, for example, giving the child a homework to do instead of taking electronics from him.
Thank you for posting such a great article. Keep it up mate.
ReplyDeleteपीडीएस बिहार
Good information. Lucky me I recently found your site by
ReplyDeleteaccident (stumbleupon). I have book-marked it for later!
토토사이트
I'm reading it well. This is something that Your post has really helped me a lot 안전공원추천
ReplyDeleteNBA superstar Stephen Curry participated in 사설토토사이트 the game wearing basketball shoes engraved with Hong Kong's famous actor's face
ReplyDeleteWohh exactly what I was searching for, 토토검증업체 it for I should state and much obliged for the data. Instruction is unquestionably a sticky subject
ReplyDeleteI think that is among the so much significant info for me.
ReplyDeleteAnd i am satisfied reading your article. However should remark on few basic issues, The
website style is perfect, the articles is
truly nice : D. Good process, cheers경마
Thanks for the blog filled with so many information. Stopping by your blog helped me to get what I was looking for. Now my task has become as easy as ABC. 안전놀이터
ReplyDeleteMany thanks for the article, I have a lot of spray lining knowledge but always learn something new. Keep up the good work and thank you again. 온라인슬롯
ReplyDeleteYou actually make it look so easy with your performance but I find this matter to be actually something which I think I would never comprehend. It seems too complicated and extremely broad for me. I'm looking forward for your next post, I’ll try to get the hang of it! Feel free to visit my website;
ReplyDelete야설
It is perfect time to make some plans for the future and it is time to be happy. I've read this post and if I could I desire to suggest you some interesting things or suggestions. Perhaps you could write next articles referring to this article. I want to read more things about it! Feel free to visit my website; 일본야동
ReplyDeleteI want you to thank for your time of this wonderful read!!! I definately enjoy every little bit of it and I have you bookma rked to check out new stuff of your blog a must read blog! Feel free to visit my website;
ReplyDelete국산야동
Its an amazing website, really enjoy your articles. Helpful and interesting too. Keep doing this in future. I will support you. Feel free to visit my website; 일본야동
ReplyDeleteSuch a very useful article. Very interesting to read this article.I would like to thank you for the efforts you had made for writing this awesome article. Feel free to visit my website; 한국야동
ReplyDeleteOf course, your article is good enough, 사설토토사이트 but I thought it would be much better to see professional photos and videos together. There are articles and photos on these topics on my homepage, so please visit and share your opinions.
ReplyDeleteHi, I read your blogs like every week. Your story-telling style is awesome, keep doing what you’re doing!
ReplyDeletehttps://www.betmantoto.pro
Amazing blog ever come across on the internet. In case you need online assignment help, then sourceessay.com will be the best place to learn the amazing writing techniques from assignment writers. Write that essay Adelaide
ReplyDeleteWhen I read your article on this topic, the first thought seems profound and difficult. There is also a bulletin board for discussion of articles and photos similar to this topic on my site, but I would like to visit once when I have time to discuss this topic. 온라인슬롯
ReplyDeleteI figure this article can be enhanced a tad. There are a couple of things that are dangerous here, and if you somehow managed to change these things, this article could wind up a standout amongst your best ones. I have a few thoughts with respect to how you can change these things. 메이저놀이터
ReplyDeleteNice to meet you. Your website is full of really interesting topics. It helps me a lot. I have a similar site. We would appreciate it if you visit once and leave your opinion. 안전놀이터추천
ReplyDeleteGreat Info. Thanks for sharing. It was really helpful. hat's a great value bomb you are dropping here. Nice to see this post. Nice info. I was getting an error code called Quickbooks update error 1328
ReplyDeletein the popular accounting tool called Quickbooks. Hope this helps.
really nice blog. Quickbook is an accounting software it really very excellent working u can go through and check but few days before i found an error on it quickbooks error 404 but now its resolved.
ReplyDeleteThank you for your post, I look for such article along time, today i find it finally. this post give me lots of advise it is very useful for me. nice i like it.
ReplyDelete카지노사이트
Excellent work! One thing I’d really like to reply to is that fat burning plan fast is possible by the suitable diet and exercise. A person’s size not just affects appearance, but also the quality of life. Self-esteem, depressive disorders, health risks, as well as physical abilities are affected in weight gain. It is possible to do everything right but still gain. In such a circumstance, a problem may be the offender. While a lot of food instead of enough exercise are usually the culprit, common health conditions and traditionally used prescriptions can greatly increase size. I am grateful for your post here.
ReplyDelete무료야설
대딸방
타이마사지
안마
바카라사이트
Many thanks for the article, I have a lot of spray lining knowledge but always learn something new. Keep up the good work and thank you again. How much Money does Soccer Players Make
ReplyDeleteHow to Activate the Roku Channel or other Free Channels and Premium Channels to your Roku TV, Roku stick.You first need to Create an Roku Account and Activate it then you can search for your favourite channel and favourite shows, then you can download it to your roku account and activate it. If you need any help in process we can provide you the assistance on Activating the Roku and the Channels on Roku.
ReplyDeleteI appreciate your information in this article. It’s smart, well-written and easy to understand. You have my attention on this subject. I will be 토토
ReplyDeleteThis blog is very helpful for everyone and after reading this blog, I got to learn a lot and I grew my friend too much about this blog, I hope you do blog posts like this. best seaward Website Development Services in USA, JKM Soft Solutions has acquired a great status and occupied with catering customers with its select WordPress
ReplyDeletewebgirls.pl With regards to fighting candidiasis, patients often times have their job remove for them. The reason being infections can simply grow to be constant and continuing. Bearing that in mind, in the following paragraphs, we are going to present a variety of some of the finest confirmed candidiasis remedy and prevention recommendations close to.
ReplyDeletewebgirls In terms of combating infections, patients usually have their job eliminate to them. Simply because yeast infections can readily become chronic and continuous. Bearing that in mind, in this post, we are going to present a wide range of the best confirmed candidiasis remedy and avoidance suggestions around.
ReplyDeleteAirtel Tower Office - Airtel tower installation and complain
ReplyDeleteAirtel tower agreement letter & Airtel tower approval letter
Airtel tower installation customer care number & contact no
Submit Airtel tower complaint online & get solved in 24hours
Registration open for Airtel mobile tower installation 2022
Airtel tower head office contact number and helpline number
Documents require for Airtel mobile tower installation
Airtel tower installation process and details step by step
https://gamebegin.xyz It is possible to training by itself. A pitching device permits you to establish the speed in the golf ball. By loading many baseballs in to the machine, you can practice hitting without having a pitcher. This electronic digital machine is good for these who want to training baseball by yourself. Pitching equipment may be gathered at the community showing off goods shop.
ReplyDeletehttps://gameboot.xyz You see them on mags as well as on TV, women and men who look like their forearms and legs will explode as his or her muscle groups are really big! There is no will need that you can consider your body to that particular stage when you don't prefer to, as the easy methods in this post will help you to build muscles in the wholesome way.
ReplyDeleteafghanisthan falls under traditional legalization process. All the document has to be ratified from the concerned embassy or the counsulate.Educational certificate attestation we have two procedures Afghanistan Embassy Attestation Service , Afghanistan, is one of the major islamic country having the capital at Kabul surrounded by land multiethnic country located in the middle of south-central Asia.
ReplyDeleteYou've completed in excellent work. t suggest to my frtends ind personilly wtll certitnly dtgtt. t'm conftdent they'll be gitned from thts webstte bitmain antminer s19
ReplyDeleteThanks for a very interesting blog. What else may I get that kind of info written in such a perfect approach? I’ve a undertaking that I am simply now operating on, and I have been at the look out for such info. Yes i am totally agreed with this article and i just want say that this article is very nice and very informative article.I will make sure to be reading your blog more. You made a good point but I can't help but wonder, what about the other side? !!!!!!Thanks This is really a nice and informative. 토토
ReplyDeleteI¡¦ve been exploring for a little for any high-quality articles or weblog posts on this kind of area . Exploring in Yahoo I eventually stumbled upon this site. Studying this information So i¡¦m happy to exhibit that I’ve a very excellent uncanny feeling I discovered just what I needed. I most indisputably will make certain to don¡¦t put out of your mind this web site and give it a glance regularly. 검증된놀이터
ReplyDeleteThis is such a great resource that you are providing and you give it away for free. I love seeing blog that understand the value. Im glad to have found this post as its such an interesting one! I am always on the lookout for quality posts and articles so i suppose im lucky to have found this! I hope you will be adding more in the future 온카판
ReplyDeleteIf you are going for most excellent contents like myself, just pay a visit this site all the time for the reason that it presents feature contents, thanks..Thank you, I’ve just been looking for information about this subject for ages and yours is the greatest I’ve discovered till now. But, what about the bottom line? Are you sure about the source? 토토지식백과
ReplyDeleteI found useful information on this topic as Now i’m focusing on a company project. Thank you posting relative information and its currently becoming easier to complete this project 헤이먹튀
ReplyDeleteYou actually make it look so easy with your performance but I find this matter to be actually something which I think I would never comprehend. It seems too complicated and extremely broad for me. I’m looking forward for your next post, I’ll try to get the hang of it! 토토사이트주소
ReplyDeleteHi..
ReplyDeleteNice Blog very good content I think that a healthy era of big data can be maintained only when such high-quality information I have recently corrected
QuickBooks License Error with the help of QuickBooks tools.
i definitely want to tell you that i am new to weblog and simply apprec, high-quality profession! You undergo thru a high-quality vacancy. I sanity in reality quarry it moreover personally advise to my buddys. I am self-possessed they willpower be benefited from this scene. 메이저놀이터모음
ReplyDeletethat type of info in such a great way of writing? I’ve a presentation next week, and that i’m on the search for such data. Thanks for the publish i in reality found out something from it. Very good content material on this website online constantly searching ahead to new publish. After have a look at most of the weblog articles with your website now, we surely consisting of your way of blogging. I bookmarked it to my bookmark website online list and you will be checking returned quickly. Pls check my web page likewise and tell me in case you agree. i'm frequently to running a blog i sincerely appreciate your posts. The thing has simply peaks my interest. My goal is to bookmark your internet weblog and hold checking deciding on information. Exceptional submit but , i was trying to recognise if you may write a litte greater on this problem? I’d be very grateful if you may complicated a bit bit extra. Bless you! I experience you because of your whole paintings in this blog. My daughter loves accomplishing studies and it’s without a doubt easy to understand why. The general public recognize all the compelling way you deliver important items through the web weblog and invigorate participation from the others on that problem count even as our own female is constantly discovering a whole lot. Take pleasure inside the final part of the 12 months. You’re wearing out a effective task. Best publish. I analyze some element a whole lot more difficult on diverse blogs everyday. It will usually be stimulating to learn how to study content the use of their organization writers and exercising something from their shop. I’d choose to apply certain collectively with the content material on my weblog whether you don’t mind. Natually i’ll supply you with a link for your net weblog. Appreciate your sharing. Satisfactory examine, i simply handed this onto a pal who was doing some studies on that. And he definitely offered me lunch due to the fact i discovered it for him smile so let me rephrase that: thanks for a few other informative weblog. Where else ought to i am getting that type of information written in such an ideal manner? I've a venture that i’m just now working on, and i've been on the look out for such statistics . Beautifully written article, if only all bloggers supplied the equal content as you, the net could be a miles better area. It’s very informative and you're glaringly very knowledgeable on this area. You've got opened my eyes to various perspectives on this topic with exciting and strong content material. Paintings isn't longer a place pay effectively using our fee machine, launch bills in step with a agenda of milestones you set, or pay most effective upon finishing touch. You're on top of things, so that you get to make choices . Exciting subject matter for a weblog. I've been looking the net for fun and came upon your internet site. Excellent post. Thank you a ton for sharing your know-how! It is brilliant to see that some humans nevertheless put in an effort into managing their web sites. I'll be sure to check lower back again actual quickly. That is honestly exciting reading. I am happy i discovered this and were given to read it. Amazing process on this content. I like it. 스포츠토토
ReplyDelete"first rate facts sharing .. I'm very glad to have a look at this article .. Thanks for giving us go through data. Great exquisite. I recognize this put up. I immoderate respect this put up. It’s tough to lo"" .
ReplyDeleteRemarkable article, it is particularly useful! I quietly began in this, and I'm becoming more acquainted with it better! Delights, keep doing more and extra impressive .
Really impressed! Everything is very open and very clear clarification of issues. It contains truly facts. Your website is very valuable. Thanks for sharing." 메이저사이트
this is an exquisite detail for sharing this useful message. I am dazzled by using the facts you have got on this weblog. It causes me from a couple of points of view. A debt of gratitude is in order for posting this yet again. Very informative submit! There is lots of information right here which could help any enterprise get began with a successful social networking marketing campaign. You made such an exciting piece to examine, giving every situation enlightenment for us to gain information. Thank you for sharing the such records with us to study this... I in reality like your weblog. Incredible article. It is maximum evident, human beings should analyze earlier than they may be capable of . 파워사다리
ReplyDeletewhat i do not comprehended is in all fact the manner you aren't simply considerably more very plenty desired than you may be at this moment. You're insightful. You notice alongside those strains basically regarding the matter of this situation, added me as i would love to assume trust it is whatever but a first-rate deal of fluctuated elements. Its like women and men are not protected except if it's some thing to attain with female crazy! Your person stuffs extremely good. 먹튀검증센터
ReplyDeletei'm happy to find out such large numbers of precious records here within the publish. We need training consultation greater strategies in such way. A debt of gratitude is in order for sharing. Superb blog! I should want to thank for the undertakings you've got made in growing this post. I am believing a similar exceptional work from you in some time furthermore. I predicted to thanks for this locations! Grateful for sharing. Terrific locations! I certainly revel in virtually reading all your weblogs. Really desired to tell you which you have people like me who appreciate your art work. Without a doubt a fantastic post. Hats off to you! The records that you have supplied can be very beneficial. I need you to thank in your season of this excellent have a look at!!! I definately recognize every and each piece of it and that i have you ever bookmarked to take a look at new stuff of your blog an unquestionable requirement read blog! Cool you inscribe, the information is truely salubrious in addition captivating, i'll provide you with a hook up with my scene . The submit may be very incredible around the area many humans need to study this shape of submit i'm moreover a part of them and after the reading supply accurate critiques . I study a brilliant deal of stuff and i found that the method for maintaining in contact with clearifing that precisely want to nation became exquisite so i am stimulated and ilike to return once more again in future.. Useful facts .. I'm very happy to observe this article.. Thanks for giving us this useful records. Exceptional walk-through. I understand this publish. Such an in particular massive article. To a amazing degree fascinating to observe this article. I need to need to thanks for the undertakings you had made for growing this amazing article . Top notch blog. I took pleasure in scrutinizing your articles. That is fantastically a exquisite scrutinized for me. I have bookmarked it and i am suspecting scrutinizing new articles. Retain doing superb! I revel in extremely cheerful to have visible your website web page and expect this kind of huge extensive form of all of the more attractive situations perusing proper right here. Heaps preferred once more for every one of the points of interest. i need you to thank for your season of this exquisite examine!!! I definately apprehend each and each piece of it and that i have you ever bookmarked to look at new stuff of your weblog an unquestionable requirement study blog! Hold the great do the activity, once i recognize numerous threads within this net net page in addition to i am sure that a international-huge-web weblog website on-line is typically proper useful possesses offered luggage linked with outstanding statistics. I havent any word to welcome this put up..... Certainly i am stimulated from this put up.... The character who make this put up it was an amazing human.. Thank you for imparted this . Exquisite weblog. I took pleasure in scrutinizing your articles. This is extraordinarily a incredible scrutinized for me. I've bookmarked it and i'm suspecting scrutinizing new articles. Keep doing terrific! Suitable placed up. Thank you for sharing with us. I truly cherished your way of presentation. I loved studying this . Thanks for sharing and hold writing. It is ideal to examine blogs like this. I suppose this is one of the most massive facts for me. And that i’m glad analyzing your article. However need to statement on a few full-size topics, the net web page fashion is best, the articles is in reality splendid : 토토사이트코드
ReplyDeletefirst rate post! I am absolutely getting ready to across this facts, is very helpful my friend. Also exquisite weblog here with all the treasured data you've got. Keep up the coolest paintings you're doing right here. This is an excellent publish i visible thanks to proportion it. It's far certainly what i desired to look wish in future you will maintain for sharing this type of super submit. First-rate article, it become especially helpful! I actually began in this and i am turning into greater acquainted with it better! Cheers, keep doing first rate! Exciting and interesting data may be observed on this subject matter right here profile really worth to peer it. Thank you for a completely thrilling blog. What else may additionally i get that kind of info written in this kind of perfect technique? I’ve a project that i am genuinely now working on, and i have been on the appearance out for such info. You there, that is extraordinary post right here. A debt of gratitude is in order for setting aside the attempt to post such sizeable statistics. Great substance is the thing that continuously gets the guests coming . Wonderful data sharing .. I am very happy to examine this newsletter .. Thanks for giving us go through info. First rate high-quality. I recognize this submit. The website is very good and has a excessive value for creativity . 토토사이트
ReplyDeletei perpetually visit your blog and retrieve the whole lot you submit right here however i by no means commented however in recent times once i noticed this post, i couldn’t stop myself from commenting right here. Quality mate! I can see that you are an professional at your field! I'm launching a internet site quickly, and your records can be very useful for me.. Thanks for all of your assist and wishing you all the fulfillment for your business. I simply found your helpful weblog and expected to express that i've honestly thoroughly loved scrutinizing your weblog passages. I may be your nonstop traveller, this is unquestionable. Thanks for all of your help and wishing you all the success in your business. Hey! That is type of off topic but i need some advice from a longtime blog. Is it very tough to set up your personal weblog? I’m not very techincal but i'm able to determine matters out quite speedy. I’m considering setting up my own however i’m not sure in which to begin. Do you've got any thoughts or tips? Respect it . Great information thank you that is pleasant and amazing thanks for proportion us. Top notch weblog…i can definitly percentage your blog with different people. Thank . I simply could not leave your internet site before telling you that i sincerely loved the top satisfactory data you present for your site visitors? Could be returned once more regularly to test up on new posts. 먹튀검증사이트
ReplyDeletei basically want to disclose to you that i'm new to blog and surely loved this weblog internet site. Possibly i am going to bookmark your blog . You totally have fantastic stories. Cheers for supplying to us your . What a pleasant comment! First-class to meet you. I stay in a different united states of america from you. Your writing may be of outstanding assist to me and to many other human beings dwelling in our usa. I used to be seeking out a publish like this, however i finally observed . I simply couldn't leave your website before telling you that i truely loved the top best information you gift to your traffic? Will be returned once more often to check up on new posts. 메이저토토사이트
ReplyDeleteExcellent Post. I appreciate your knowledge and your hard work. Thanks for sharing with us.Are you looking for dairy franchise online GetDistributors provides latest Paneer franchise opportunities in India. Find complete details of Paneer franchises or open franchise store with low cost .Contact our Dairy Franchise team & learn the benefits of investing in the best franchise.
ReplyDelete
ReplyDeletethank you!
블랙잭사이트
I look forward to your kind cooperation.
블랙잭사이트
It is a wonderful effort and as well a motivating blog article with amazing contents; keep posting such an interesting updates. I will be a regular reader. Thanks so much for sharing. Also visit post utme past questions for oau pdf
ReplyDeleteslot game 6666 เกมส์สล๊อตออนไลน์ slot online สล็อต เล่นง่ายได้เงินจริง ระบบ ฝาก-ถอน AUTO 30 วินาที เพียงแค่นั้น สล็อตแจกเครดิตฟรี slotgame6666.com มาแรงที่สุดในชั่วโมงนี้
ReplyDeleteslot siteleri
ReplyDeletekralbet
betpark
tipobet
betmatik
kibris bahis siteleri
poker siteleri
bonus veren siteler
mobil ödeme bahis
MRCMJ
kralbet
ReplyDeletebetpark
tipobet
slot siteleri
kibris bahis siteleri
poker siteleri
bonus veren siteler
mobil ödeme bahis
betmatik
44QB
saya sangat berterimakasih karena sudah membagikan informasi ini
ReplyDeleteIf you are loo대한총판연합
ReplyDelete"저는 귀하의 웹 사이 완내스 카지노
ReplyDeletepg โปรโมชั่น พิเศษสุดๆไว้ต้อนรับสมาชิกใหม่ของพวกเราด้วยโบนัสโปรโมชั่น pgslot สุดพิเศษรับโบนัส 50% สูงสุด 500 บาทดังนี้พวกเรายังได้ตระเตรียมโปรโมชั่นพิเศษอื่นๆให้กับสมาชิก
ReplyDeletepgslotccapp เป็นทางเลือกหนึ่งที่ควรลองใช้งานครับ ไม่ว่าจะเป็นผู้เล่นที่มือใหม่หรือมืออาชีพก็สามารถเข้าใช้งานได้ง่ายๆ PGSLOT และรับประสบการณ์การเล่นเกมส์ที่น่าตื่นเต้นและสนุก
ReplyDeleteโหลด pg slot ทดลองเล่นฟรี คุณกำลังมองหาประสบการณ์การเล่นเกมออนไลน์ที่น่าระทึกใจอยู่หรือไม่? ทดสอบเล่นpg ไม่ต้องมองหาที่แหน่งใดนอกเหนือจาก PG SLOT สมัครขณะนี้และก็เริ่มเล่น
ReplyDeletepgslot1234 สล็อตออนไลน์ การพนันหรือเกมคาสิโนในต้นแบบออนไลน์นั้นจะต้องบอกเลยว่าหนึ่งในเกมที่มาแรงที่สุดนั้นจำเป็นที่จะต้องชูให้กับเกมตู้ยอดนิยมอย่าง PG สล็อต อย่างแย้งมิได้
ReplyDeleteเบอร์ มงคล สำหรับ PG นักเสี่ยงโชค สล็อตแตกง่ายมากยิ่งกว่าเดิมก็เลยเป็นที่เรียกร้องของมนุษย์ล้นหลาม เบื้องต้นของชาวไทยนั้นประทับใจการลุ้นโชค PG แสวงโชคลาภ เพื่อผลที่มีผลดีต่อโชคชะตา
ReplyDeleteI really enjoyed this post and hope you write more like this
ReplyDeletehttp://images.google.co.uk/url?q=https%3A%2F%2Fkomakdon.com
ReplyDeleteI’m not very internet smart so I’m not 100% sure. Any tips or advice would be greatlyd made me feel a lot. Please feel 메이저검증업체 free to share such good information.
ReplyDeleteThese foods contain a high amount of salt, which leads to high blood pressure and heart disease. In general, the more ingredients 9xmovies on the label, the more processed the item.
ReplyDeleteAllows you to download, install, and configure setup on your PC, Mac and smartphones as well. Canon ij setup is the software to install Canon printer wirelessly.
ReplyDeleteij.start.canon is the solution for easy Canon printer drivers download. Https //ij.start.cannon allows you to install and set up a Canon inkjet printer and ensure that you receive outstanding printing results Https //ij.start.cannon
ReplyDeleteMagellan roadmate Updates
ReplyDeleteSome popular Gps devices like- Magellan devices like magellan maestro 3200,magellan roadmate 1440,magellan maestro 4040, magellan roadmate 5235t-lm,magellan roadmate 1700,magellan roadmate 1470, and other old and newer models. We’ll help you to get easy maps, software / Firmware updates.
Well-written information. Very impressive and to the point
ReplyDeleteHave a look at my new blog:Final Draft Activation Code Crack 2023
slotv9 เว็บไซต์ คุณภาพดียอดเยี่ยมภาพที่ชัดเจนเสียงไม่แตกกราฟฟิคสายงวมหมุนแตกง่ายกับพวกเรา pg slot เว็บไซต์เหมาะสมกับ คุณมากที่สุด ในตอนนี้
ReplyDeleteThat’s what I love about your content. You have pour out your heart on it.
ReplyDeleteI am mainly passionate about your outstanding achieve!
ReplyDeleteGood info. Lucky me I reach on your website by accident, I bookmarked it.
ReplyDeleteI really like and appreciate your blog.Really looking forward to read more. Cool.
ReplyDeleteMajor thanks for the post.Thanks Again. Keep writing.
ReplyDeleteI appreciate you sharing this blog article.Much thanks again. Want more.
ReplyDeleteSome truly nice and useful info on this site, too I conceive the layout has wonderful features.
ReplyDeleteDeference to article author, some good selective information.
ReplyDeleteThis is such a great resource that you are providing and you give it away for free.
ReplyDeleteThis is an awesome motivating article.
ReplyDeleteI am realy extremely glad to visit your blog.
ReplyDeleteI’m glad that you just shared this helpful information with us.
ReplyDeleteGreetings! Very helpful advice within this post!
ReplyDeleteThis website is very useful and beautiful. thank you.
ReplyDeletethanks for sharing this type of useful article to read, keep it up!
ReplyDeletethis piece of writing is pleasant and very informative.
ReplyDelete
ReplyDeleteI admire this article for the well-researched content and excellent wording.
ฝาก20รับ100 pg ล่าสุด การฝากถอนในเกมสล็อต PG SLOT เป็นกระบวนการที่ง่ายสะดวกสบายทำให้ผู้เล่นสามารถเข้ามาเล่นเกมได้โดยไม่มีความยุ่งยากมากมาย นี้คือขั้นตอนที่ทำให้การฝากถอนใน PG Slot
ReplyDeleteΔεν είναι η πρώτη φορά που επισκέπτομαι αυτόν τον ιστότοπο,
ReplyDeleteεπισκέπτομαι αυτή την ιστοσελίδα καθημερινά και παίρνω ωραίες πληροφορίες από εδώ όλη την ώρα.
Thanks for sharing such a nice information.
ReplyDeleteTower installation on land is a critical process, especially for telecommunications and broadcasting. Proper site selection, safety measures, and adherence to regulations are key for a successful installation. Whether it's for a cell tower, radio, or wind turbine, a sturdy foundation and skilled workforce ensure long-term stability and performance. Additionally, community engagement and environmental assessments play vital roles in mitigating any potential impact. Efficient tower installation supports improved connectivity and infrastructure development in both urban and rural areas.
fghngfhfgjjkghjk
ReplyDeleteصيانة افران بمكه
cbcvncvnfbjmhg
ReplyDeleteصيانة افران بمكه
كشف تسربات المياه بالدمام CNHvV5KhxI
ReplyDeleteشركة كشف تسربات المياه بالقطيف THDP2cUWgB
ReplyDeleteΕκτιμώ πραγματικά αυτή τη θέση. Έψαχνα παντού γι' αυτό! Δόξα τω Θεώ, το βρήκα στο Bing. Μου φτιάξατε τη μέρα! Σας ευχαριστώ και πάλι
ReplyDeleteشركة عزل اسطح بالقصيم ouS5Dg8ZQM
ReplyDeleteشركة تنظيف سجاد بالاحساء mjJoeoKyks
ReplyDeleteشركة مكافحة حشرات بالقصيم xIu4ieOgoZ
ReplyDeleteشركة عزل أسطح بالدمام VkhZeGNJCL
ReplyDeleteشركة تنظيف مكيفات بالدمام C6vhloo6Oe
ReplyDeleteI just love to read new topics from your blog.
ReplyDeleteNice Blog. Thanks for sharing with us. Such amazing information.
ReplyDeleteI appreciate your post thanks for sharing the information.
ReplyDeleteVery Interesting and amazing how your post is! It Is Useful and helpful for me That I like it very much.
ReplyDeleteبالتوفيق اعمال مميزة شارك اعمالنا تُعد الخيار الأمثل لكل من يسعى لتحسين جودة حياته المنزلية من خلال خدمات تنظيف شاملة تسليك مجاري محترف، ومكافحة فعالة للحشرات شارك اعمال شركة تسليك مجاري بسيهات التزامها بالجودة والاحترافية يجعلها تبرز بين الشركات الأخرى ويضعها في مقدمة قائمة الخيارات لكل من يرغب في تحويل منزله إلى بيئة مثالية .
ReplyDeleteThank you so much for sharing this informative post. Really i got exact information what i was searching Hot Rolling Mill Manufacturers to know about our service.
ReplyDeleteI’ve noticed no contract wifi becoming more popular lately, and Monthly Internet Rental is often recommended for it.
ReplyDeleteThe explanation of Base64 encoding really drives home how data transformation works at the binary level. For anyone managing infrastructure, understanding these low-level concepts translates to better system design. By the way, if you ever need fast hvac emergency service, that directory has local contractors across all 50 states.
ReplyDeleteHello, It looks really great!! Your writing is impressive.
ReplyDelete