 |
| Awww... |

I have given several talks and courses on Apache Hive and Pig and other new-ish ‘Big Data’ languages built upon Hadoop and MapReduce. These technologies implement an alternate approach to relational from SQL while still retaining the character that makes them DSLs within the domain of relations/tables. In the case of Hive, the syntax is nearly the same as SQL. In the case of Pig, the syntax has inspired much confusion, and not enough love. In both cases, the semantics are nearly the same with SQL.
During these talks, I have stressed several points about the nature of database technology, unix command lines, data serialization and higher-order functional programming that I will now try to boil down to a set of coherent posts. In attempting this, I hope to anchor these themes around the unity of a mathematical concept, the relation. Ideally this (and following) posts will be both a comment on the mathematical underpinnings that have driven multiple multi-billion dollar industries (the 70’s relational boom, and the current Big Data fervor), and on the social/psychological/marketing forces that drive us to differentiate technologies from one another.
But to start this, we need to understand the foundational notion of the relation.
What the heck is a Relation?
Attempt 1: A relation is a subset of a cartesian product.
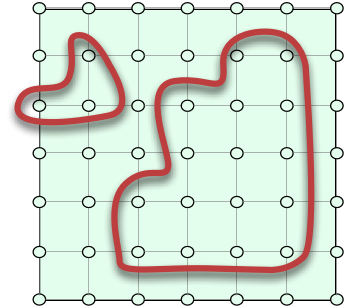
Attempt 2: A relation is a table.
Yes. This is correct too. It provides an alternate explanation and one that everyone who has ever worked in the IT field should be familiar with, ad nauseum. But how can this be the same as the first definition, that “a relation is a subset of a cartesian product”? Actually, what the heck is a “cartesian product”, and what does this have to do with a table again?
We are going to need to spend some time reconciling these two different manifestations. We will probably need to learn some new terminology, like set, domain, and cartesian product. But before we do that, let’s try a couple more explanations.
Attempt 3: A relation is a generalization of a function.
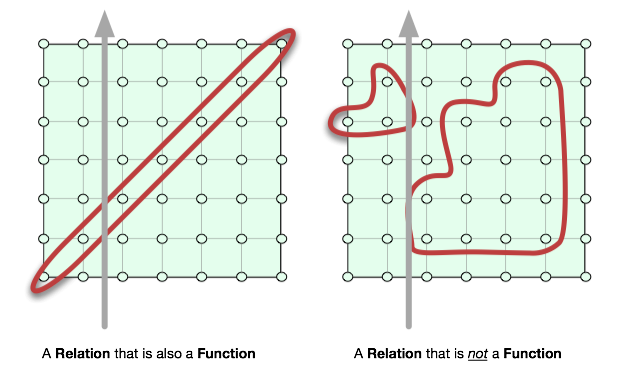
This too, provides us a concise answer, and is yet another explanation that we will need to reconcile. Very mathematical. Very true. But dry, and seemingly unrelated. (For what it’s worth, the grey arrow is the famous vertical line test).

I’m afraid that if you found Attempt 1 and 3 off putting, this one will bumfuzzle you with its terseness. It has something to do with another term that you might have heard: a predicate, which is a function that assigns truth-values.
Are all these things the same thing? And what does this have to do with databases? with Prolog/Datalog? with Hive, with Pig, with SQL? with logic? with predicate calculus? with relational algebra? with inference? with knowledge? with truth?
It seems we have have started with something simple, and gotten ourselves into quite a mess. We claimed that we needed to reconcile these notions, (these manifestations), of this abstraction that we call a relation. But in order to do this we will need to discuss things like sets, predicates, domains, ordering, functions, operators, tuples, individuals, facts, ground terms, truth-values etc. We are entering the realm of meta-mathematics.

The Many Faces of the Relation
Let us list out the ways we have just described a relation:
- as an arbitrary subset of an arbitrary cartesian product
- as the generalization of a function
- as a table
- as a predicate function (‘a property that assigns to every k-tuple a truth-value’)
To reconcile all these notions we can do a pairwise match and compare each interpretation against the other. Let’s start with the two interpretations that will give us the most traction for the terminology that they introduce: a relation as a table versus a relation as an arbitrary cartesian product subset.
The Table Versus the Cartesian Subset

To get this started on the right foot we need to nail down the terms dimension, cartesian product, and domain. This is not daunting, and most everyone intuitively knows what they are, they have just never used the terms in a different context or realized the connection. Rather than belabor the point, we are going to show the following equalities:

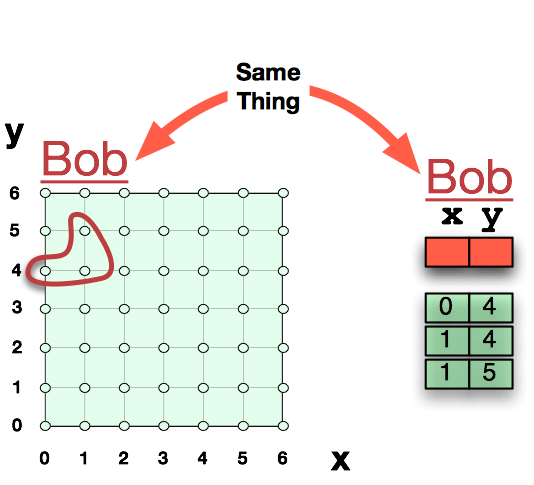
It’s helpful to start with something simple, like plain old vanilla x and y values on a normal x-y plane. This was the original Cartesian plane, as willed into existence by Descartes as he lay in bed and stared at a bug crawling up and down a wall.
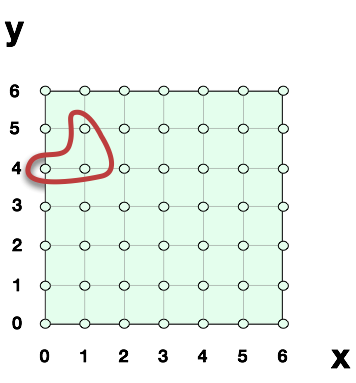
In this case, our cartesian product is a multiplication of two dimensions x, and y. If we assume that x is an integer, then we are saying its domain is an integer. If we assume that y is an integer, then we are saying its domain is an integer. Together, these two domain multiplied give us the cartesian plane of (x,y). An individual on this plane is also called a tuple, or a point -- all three words are the same.
As we see above, we have selected an arbitrary subset of this cartesian product. This subset has three individual/tuples/points: {(0,4), (1,4), (1,5)}. We could list these point out in a table if we wanted:

and just like that we have shown the equivalence between a table and a subset. We see that a row is the individual, or the tuple, or the point. They are the same. We see that a column is a dimension. We see that the column’s type is the same thing as a domain.
Let’s do one more thing. Let’s give the relation a name. Let’s call it “Bob”. Finally, we have a formal relation as described by Codd.
Let’s do one more thing. Let’s give the relation a name. Let’s call it “Bob”. Finally, we have a formal relation as described by Codd.
Abstracting from Numbers
While Descartes thought about numbers, nothing prevents us from using the idea of dimensions in a non-numeric way. We can make our dimension anything we want. First off, rather than infinite numbers, we can have finite colours, or finite vegetables.
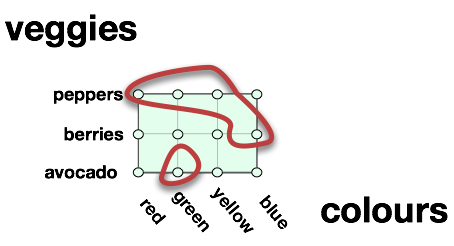
In the above diagram, we see a green rectangle that represents the entire universe of possible coloured vegetables if and only if we assume that there are only 4 colours {red,green,yellow,blue} and 3 vegetables {peppers,berries,avocado}. By multiplying these out, we see that the entire universe of individuals possible (called a domain of discourse) is 12. This is a finite cartesian product. Nevertheless, we can take any arbitrary subset of this cartesian product, name it, and we have ourselves a relation.
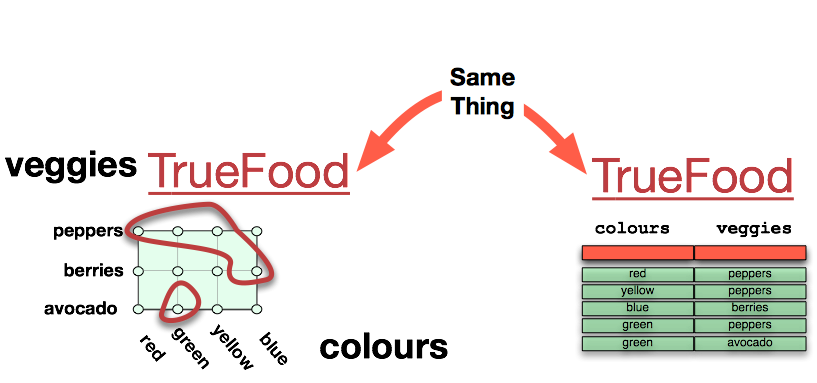
Here we can see that we have selected a subset of five tuples/individuals/points, and simultaneously shown this subset as a listing in a table. We have named this relation TrueFood, presumably under the assumption that these particular individuals represent a listing of those things that are actual foods.
Moving to Higher Dimensions
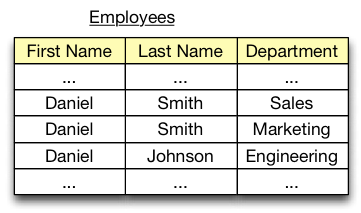
Finally, let us consider the classic table example, the Employee table, in which the FirstName, LastName, and Department may capture a listing of everyone in a company. If we draw an analogy with spatial dimensions, then we can imagine last names running across the X-coordinate, first names running on the Y-coordinate and departments running on the Z-coordinate.
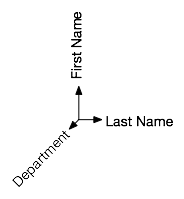
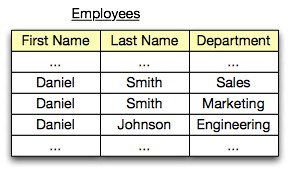
As shown above, this is merely a spatial representation of three different dimensions. There is no inherent ordering, much like the example with veggies and colouring. Nevertheless, this is absolutely a valid visual metaphor. The entire space of possible cartesian products would range across individuals of 3-tuples.
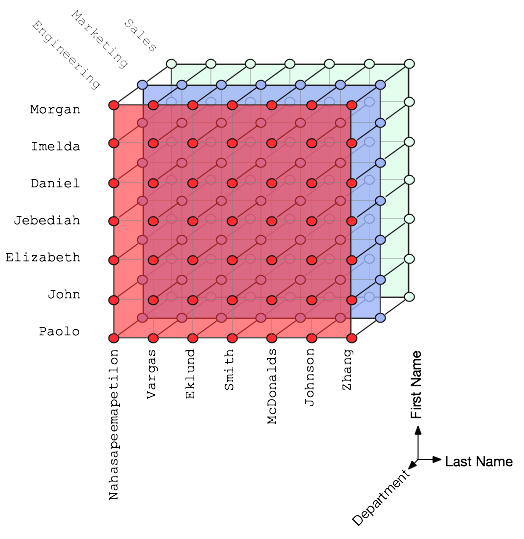
Just to make things simple, imagine a universe in which there were only 7 first names, 7 last names, and 3 departments. In this finite 3-dimensional space, there are 63 possible individuals/points/tuples. Now imagine an arbitrary subset of this universe of individuals.

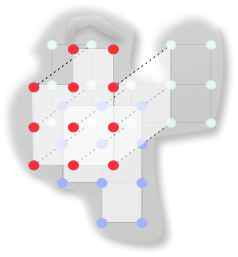
We can name this subset Employees, and we have a relation that represents our listing of all the people in our universe who we believe to be employees within our company. It is this final point that provides us a hint on how we can reconcile our metaphor further, by drawing out the analogy to statements of facts. This allows us to see our table not only as a subset of the entire universe of people, but as our collected knowledge about who is an employee and who is not (* we will return to this when we examine our last statement that a “relation is a property that assigns to every k-tuple a truth-value”).

We are tantalizingly close to seeing how relations may be manifested within the world of logic -- mainly in understanding that almost all logical systems start with statements of fact -- “Socrates is a man”. But before we continue down that path, let’s talk about our understanding of relations as generalizations of a function.
Cartesian Subsets Versus Relation-is-a-generalization-of-a-Function

Now that we understand how a relation may be viewed as an arbitrary subset in cartesian space, it makes sense to push through and understand the statement “a relation is the generalization of a function.” This particular statement can be seen visually when we see that a function is itself a subset of cartesian space.

Above we see the classic example of a numeric function in cartesian space. Our function squares the input, and we may say that our function maps values of x to values of y. Clearly we have a subset in the thick black line that visually represents all the tuples/rows/individuals that belong to this 2-dimensional cartesian space. This function is a relation. All functions are subsets of cartesian products, and therefore all functions are relations.
But not all relations are functions! Clearly, functions are subsets that meet a particular criteria.
We used the term map because that is the standard nomenclature that is associated with the set-theoretic description of functions. Intensional or extensional debates flourish around the true nature of what a function is, but it is probably best not to get too religious about it at this point. The history of the notion of a function is a fascinating read.
Most people who remember their high school algebra remember the statement that a function passes a “vertical line test” in demanding that an input value (a domain) be mapped on only one output value (the range). This is the simple explanation of the criteria that separates the nature of a function as a subset from an arbitrary subset. The vertical line test is clearly only applicable for two-dimensional visual representations -- more generally, one might say that at least one of the dimensions represents an output or range, and that the cardinality of its projection equals the cardinality prior to projection.
We could equally have said that the function y=x2 relates the values of x and y. This is absolutely correct too. However, when we use the word maps we are adding the further constraint of the vertical line test.
Just to provide one more interesting explanation on how relations are generalization of functions. Let us compare a relational programming language, versus a functional programming language. Now, if you saw the phrase relational programming language and immediately thought SQL, then this is not quite what we mean. Instead, we are talking about general purpose programming languages alternatively known as logic programming languages. Let us compare how the relational/logic programming language Prolog would syntactically represent the addition operation from how a functional language would represent the addition operation.
The following lines of codes are valid snippets of Prolog code:
But not all relations are functions! Clearly, functions are subsets that meet a particular criteria.
We used the term map because that is the standard nomenclature that is associated with the set-theoretic description of functions. Intensional or extensional debates flourish around the true nature of what a function is, but it is probably best not to get too religious about it at this point. The history of the notion of a function is a fascinating read.
Most people who remember their high school algebra remember the statement that a function passes a “vertical line test” in demanding that an input value (a domain) be mapped on only one output value (the range). This is the simple explanation of the criteria that separates the nature of a function as a subset from an arbitrary subset. The vertical line test is clearly only applicable for two-dimensional visual representations -- more generally, one might say that at least one of the dimensions represents an output or range, and that the cardinality of its projection equals the cardinality prior to projection.
We could equally have said that the function y=x2 relates the values of x and y. This is absolutely correct too. However, when we use the word maps we are adding the further constraint of the vertical line test.
Just to provide one more interesting explanation on how relations are generalization of functions. Let us compare a relational programming language, versus a functional programming language. Now, if you saw the phrase relational programming language and immediately thought SQL, then this is not quite what we mean. Instead, we are talking about general purpose programming languages alternatively known as logic programming languages. Let us compare how the relational/logic programming language Prolog would syntactically represent the addition operation from how a functional language would represent the addition operation.
The following lines of codes are valid snippets of Prolog code:
plus(6,2,4). % Here we are saying that 6 is related to 2
% and 4 by being the result of adding 2 and 4.
% but just as equally, we can say that 4 is related
% to 6 and 2 by being that which added to 2
% gives 6.
plus(200,199,1).
plus(X,2,4)? % Under this query, we will get X=6
plus(6,Y,4)? % Here we will get Y=2
And the following line of psuedo-code is valid in any language that has functions (no need to demand the use of a full blown functional language like Haskell):
x = plus(199,1); // x will be 200 if we implemented this correctly :)
The difference in them is interesting.
While the relational language has the word plus taking 3 arguments and has no output variable, the function-like languages use 2 arguments and assigns/binds the output to a variable. The difference is one of generality. Functions promote one of the dimensions to an output, (they map all inputs/domains to an output/range). But relations assume no special direction: 6 is related to 2 and 4 by being the result of adding 2 and 4, but just as trutfully, we can say that 4 is related to 6 and 2 by being that which added to 2 gives 6.
The difference in them is interesting.
While the relational language has the word plus taking 3 arguments and has no output variable, the function-like languages use 2 arguments and assigns/binds the output to a variable. The difference is one of generality. Functions promote one of the dimensions to an output, (they map all inputs/domains to an output/range). But relations assume no special direction: 6 is related to 2 and 4 by being the result of adding 2 and 4, but just as trutfully, we can say that 4 is related to 6 and 2 by being that which added to 2 gives 6.
Finally: Comparing A Relation as a Subset versus A Relation as a Predicate Function, or A Relation is a Property that Assigns to each K-Tuple a Truth Value

Let’s keep going.
This reconciliation is very interesting, and one that confused me for a long time. Here we have gone to the trouble of saying that a relation is a generalization of a function, and now we are going to turn around and call it a function. This seemingly contradictory statement is not really contradictory, but is a result of the fact that we are at the lowest level. Things like sets, and relations and functions are the fundamental building blocks of logic, meta-mathematics and mathematics. When you are this low down then we cannot help but re-use our low-level notions to describe things in terms of another. So let’s explore this weirdness.
Here are the two equivalent statements:
This reconciliation is very interesting, and one that confused me for a long time. Here we have gone to the trouble of saying that a relation is a generalization of a function, and now we are going to turn around and call it a function. This seemingly contradictory statement is not really contradictory, but is a result of the fact that we are at the lowest level. Things like sets, and relations and functions are the fundamental building blocks of logic, meta-mathematics and mathematics. When you are this low down then we cannot help but re-use our low-level notions to describe things in terms of another. So let’s explore this weirdness.
Here are the two equivalent statements:
A relation is a property that assigns to every k-tuple a truth-value
|
A relation is a predicate function
|
So, let’s first define a predicate function: a predicate function is a function that gives a truth-value about an element. Another way of saying this is that a predicate is a function that returns an element of the set { true, false }.
The phrase “k-tuple” is mathy for an individual or element or point or row with k-dimensions. “Truth-value” is mathy for something that is either true or false. “Predicate Function” is mathy for a function that returns a boolean.
The phrase “k-tuple” is mathy for an individual or element or point or row with k-dimensions. “Truth-value” is mathy for something that is either true or false. “Predicate Function” is mathy for a function that returns a boolean.

We are still not there. How can a relation, which we know is a subset of a cartesian product, also be a predicate function? Well, look at the graphic above, where we show the Employee table/relation/subset. As you can see, the entire universe of possible people is a larger space of individuals. However, only the individuals/tuples/rows/elements of our subset are what we call employees. So, why not make our predicate function something simple like: “Is the individual X an element of the subset Employees?”.
And just like that, we have unified the notions. Our function signature looks something like this:
And just like that, we have unified the notions. Our function signature looks something like this:
EMPLOYEE(X) -> BOOLEAN
The implementation of the function would merely check to see if X was an element of the subset . This is called an indicator function. So if we were to call our function on a couple of possible individuals/tuples/rows/elements we would get
EMPLOYEE(Daniel Smith, Marketing) → TRUE
EMPLOYEE(Jebediah Vargas, Marketing) → FALSE
This is equivalent to asking, is there a row in the table with this value? If there is, then the person is an employee. If there’s not then the person is not an employee.
This is equivalent to asking, is there a row in the table with this value? If there is, then the person is an employee. If there’s not then the person is not an employee.
Tangent: This last point is a fundamental one that has different interpretations. In the Closed World Assumption, a database is complete and every tuple represents a fact. If a fact is not present, then it is false. In the Open World Assumption, a database is a collection of known facts, and the lack of a fact is not equivalent to saying that the predicate is false. See Reiter.
This is a fascinating place where philosophy meets the technical. For a concrete example of this, look to the Semantic Web effort.
The Semantic Web is a system of binary relations manifested in something called RDF triples. An RDF triple is nothing more than a single floating tuple of a binary relation, and the entire internet is a database of disperse binary tuples, representing currently-known facts. The philosophy of the Semantic Web is very much around the Open World Assumption.
|
SUPER IMPORTANT Tangent: Given everything we’ve said about these different manifestations, what does having a NULL value for one of the dimensions imply? Can you see why allowing NULLS in a database has historically really bothered a lot of people?
We can easily add a null to the table interpretation, as shown below:
 What about the predicate function interpretation, where the function needs to return either TRUE of FALSE? Are all green veggies true food? Is there one green veggie that is a true food and we just don't know which one it is? What happens if someone asks "TRUE_FOOD( "green avocado" )?" Should we return TRUE or FALSE? If we don't, and return something else, we have exited standard logic with Boolean values and entered more esoteric realms. |
Conclusion
 |
| Tree of Life |
The overriding theme for this little post, was that the notion of a relation as an abstraction provides a unifying means of thinking about data. I have never claimed that the implementation details are irrelevant. There is a reason that OLAP/MPP databases are separate products from OLTP databases -- they materialize and store their relations differently to account for different access patterns. There is a reason that graph databases are a separate product (index-free adjacency inverts the primacy in typical relational stores of the relation over the individual to be the individual over the relation). There is a reason why Prolog is a language for storing a small number of mostly-static facts of atomic tuples, while a database is a technology for storing a huge number of mostly-dynamic facts. There is a reason why database management systems exist in the first place (curated schema with a priori schema knowledge provides the management system up-front knowledge on types and indexes that make relational queries real-time).
I have also not claimed that any of these ideas are new. It is always useful, to go back and read the original source material, especially Codd’s 1972 paper where he proved that relational algebra and relational calculus (itself a modified version of predicate calculus -- a fundamental logic) were one and the same. Go read the papers of Gallaire, Minker, Reiter, Nicolas, Kowalski, whose 30 year old premises recognize the logic programming and databases are the same and propose the notion of deductive databases. (* there are dozens of source material papers I should eventually collect together into a bibliography, if I were so inclined).
In the following post: “The Occultation of Relations and Logic” we will drive home the point that relations are abstractions. Too often, people equate relations with SQL, or (worse) with database management systems (Oracle, MySQL). We will reveal the opposite, and show how relations may be used to think about the world, and how even things like shadows and log files may be interpreted as facts and tables and cartesian products, i.e. as relations.
(thanks to Dean Wampler, and Bhavana C for feedback)
Excellent post, helped connect some dots for me ;)
ReplyDeleteCould you unpack this a bit?
"""(index-free adjacency inverts the primacy in typical relational stores of the relation over the individual to be the individual over the relation)"""
I need to read this about 10 more times but really great job, consider my mind blown.
ReplyDeleteVery well explained. I understand the importance this article.
ReplyDeleteWell done!
That is a beautiful article. A really nice synthesis of functional and relational thinking. I wonder if Erik Meijer agrees, having written "SQL and NoSQL are Really Just Two Sides of the Same Coin".
ReplyDeleteAfter this read, 1-2 things suddenly appear quite obvious :-)
Bravo! Keep going!
ReplyDeleteMy mind just exploded in euphoria. Thank you for this post.
ReplyDeletequickbooks error 15106 is one such blunder that is experienced by clients. At the point when this blunder happens, the screen gets a message-Error 15106: 'The update program is harmed or the update program can't be opened.
ReplyDeleteHey your article is so informative and very creative about your post such nice features in it if you like check onquickbooks error #15215
ReplyDeletesuch a great blog you have.
ReplyDeletesquare payroll vs quickbooks both are softwae offers access anywhere anytime with there cloud-based accessed quickbooks offers 30days free trial while in squre payroll there is no free trial"
install diagnostic tool QuickBooksis designed to troubleshoot networking and multi-user errors that can occur when you open a company file. If you’re experiencing H202, H505, or 6000 series errors, this tool can help
ReplyDeleteQuickbboks is an accounting software that be used to accounting, payroll, some time user face the issue with this the company file not open and quickbook unexpected error 5 issue so here are Many methods to resolve these issues.
ReplyDeletequickbooks unexpected error 5: A QBs Repairing Guide
First You got a great blog .I will be interested in more similar topics. i see you got really very useful topics, i will be always checking your blog 카지노사이트
ReplyDelete홈카지노
Superb Blog!
ReplyDeleteThanks For Sharing Such an Amazing Post.
바카라사이트
카지노
I encourage you to read this text it is fun described ...
ReplyDelete토토사이트
먹튀검증
Hi, happy that i saw on this in google. Thanks!
ReplyDelete토토
안전놀이터
Plan for Jio tower installation 2022 - Apply Now For Jio Tower | Apply Reliance Jio Tower Installation Online | Jio tower installation monthly rent | Reliance Jio Tower Installation Apply Online and Contact Number 2022 | Jio tower installation customer care number and contact number | Jio Tower Complaint Helpline Number - Jio Tower Helpline Number | Reliance Jio Tower Installation Process Steps To Install | Jio tower installation apply online 2021 & jio advance amount
ReplyDeleteQuickbooks is use to accounting if you are the user of this software and face issue Quickbooks error 15421 you can resolve this error with log in adminastration.
ReplyDeleteAirtel Tower Office - Airtel tower installation and complain
ReplyDeleteAirtel tower agreement letter & Airtel tower approval letter
Airtel tower installation customer care number & contact no
Submit Airtel tower complaint online & get solved in 24hours
Registration open for Airtel mobile tower installation 2022
Airtel tower head office contact number and helpline number
Documents require for Airtel mobile tower installation
Airtel tower installation process and details step by step
Clients that consider hiring virtual accounting firm who use secure software have been more successful at growing their business, increasing revenue while reducing the cost for these services.
ReplyDelete
ReplyDeleteبليط هواپیما تهران دزفول
Thanks for an interesting blog. What else may I get that sort of info written in such a perfect approach? I have an undertaking that I am just now operating on, and I have been on the lookout for such info 먹튀검증 It's amazing. I want to learn your writing skills. In fact, I also have a website. If you are okay, please visit once and leave your opinion. Thank you.
ReplyDeletefastest electric unicycle
ReplyDeleteThanks for sharing us
ReplyDeleteI was reading your website.
ReplyDeleteThis is the best way to share the great article with everyone
ReplyDeleteThanks designed for sharing such a pleasant thinking.
ReplyDeleteI definitely enjoyed every little bit of it.
ReplyDeleteI really enjoyed it. keep up the good work.
ReplyDeleteI’m hoping the same high-grade blog post from you in the upcoming also.
ReplyDeleteJust wish to say your article is as astonishing. Please continue the gratifying work.
ReplyDeleteA fantabulous post. Never seen this kind of useful post. I am grateful for this
ReplyDeleteI feel very glad to find your Informative blog. Thanks a lot for sharing great content
ReplyDeleteWell done article. I'll make sure to use it wisely. Thank you for sharing
ReplyDeleteThis is a really good.
ReplyDeleteThe content you create has always caught my attention.
ReplyDeleteThanks for taking the time to discuss this.
ReplyDeletewhat an interesting blog you have here bro!
ReplyDelete