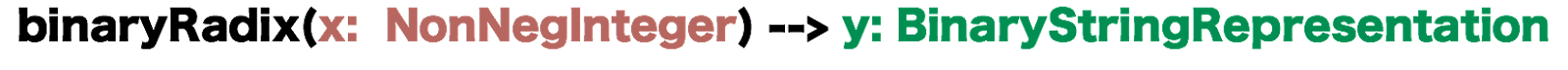Also, Why most implementations of Crockford-base32 encoding are probably incorrect
TLDR: The term base64 encoding is an overloaded term which promotes ambiguous usage. It can mean either a place-based 64-symbol encoding of a single number, or a streaming algorithm for encoding an array of octets. In common usage, it is the latter -- the same technology and IETF RFC specification that allows us to encode arbitrary binary files and place them in USENET posts and emails.
Examining the differences between the two meanings and two implementations will teach us something about ambiguity, online/stream algorithms, and that specifications are really really very important.
|
TLDR: The Crockford-base32 encoding proposal, as written here http://www.crockford.com/wrmg/base32.html, is not as clear as it could be and lacks a canonical implementation and/or test-cases.
This lack of clarity has lead most people to interpret it as a place-based 32-symbol encoding of a single number. However, the particular wording and context of his proposal implies that the Crockford-base32 encoding was meant to adhere closer to the existing base64 and base32 octet binary encodings (including padding of binary data up to a multiple of the 5-bit space).
|
The Presence of An Ambiguity
I want to use this post as a way of clearing up a confusion that seems to exist in many people's understanding of base64 (and also crockford-base32).
Because on ambiguity exists, I am going to invent my own clarifying terminology (Place-Based Single Number Encoding versus Concatenative Iterative Encoding) to attempt to disambiguate. Along the way, we will get into the nitty gritty details of binary base64-encoding (as commonly implemented in a thousand different systems) and of the radix-placed system that most people are taught as binary, octal, decimal and hexadecimal numbers.
But before I do that, let me explain what the Crockford-base32 encoding is meant to do, for those of you who have never heard of it.
Human Readable URLs
Producing URL shortening and youtube-like resource strings seems to be the raison d'être for the Crockford and other such encodings. Many famous web applications have something like this: a unique string of letters and numbers that when used within a URL/URI, provide a unique and identifying name for that resource. Resource examples range from videos, to shortened URLS, to collabedit pages, to flickr accounts.
With all these services, we desire to provide a unique identity to a resource whose cardinality may grow into the millions or billions. Certainly, the identity could be something as simple as an integer increasing in value (what the database guys call a sequence). The drawback with a sequence is that it provides people a way to guess resource identities. To counter this, we could generate a random number with insignificant chances of repeating (and of guessing) and encoding it in a high-radix encoding to shorten its string-length.
Let's examine two ways to do this.
|
Radix Place-Based Single Number Encoding System
This system is the easier of the two to explain, as it is covered in most high-schools, and CompSci 101. Nevertheless, we will go through it again.
We start with the number 101.
What is this number? Is it the number of dalmatians that should be brutally murdered, skinned, and fabricated into a woman's coat? Or is the cost of a 5 dollar foot long?
The answer is that it could be either. The number is the ultimate abstraction, that which your brain interprets, and the glyphs and the symbols are the permanent memory of that number on paper or on disk. But in-between, we need to apply a decoding to turn interpret the glyphs from symbols through numerals to a number. In binary, the glyph/symbol/numeral string of "101" can be interpreted as "five" -- just enough dollars to buy a Subway sandwich. In decimal, which most humans (without compsci/math background) take for granted, the string "101" is interpreted as "one hundred and one."
The term radix, which is synonymous with the term base, is defined as the number of unique symbols in a place-based numeric system. The radix-system that most humans use is a base-10 or radix-10 system. The symbols we have today for our numbers came to us during the Renaissance from the Arab mathematicians. We called them arabic numerals, despite the fact that the Arab mathematicians imported them from the Indians who invented the numeral 0. This special numeral 0, along with the other nine symbols, make up the most famous and consistent symbols that the world has ever seen. We all collectively own these symbols today: '0', '1', '2', '3', '4','5','6','7','8','9', and we assume that they are in this order: 0123456789.
To restate, the reason that we call this a radix-10 system is because we have 10 unique symbols. However to be a base-10 system, we do not have to use these exact symbols or in this traditional order. How weird a parallel universe there must be where, due to a transposition error, our system could have been 0123465789? Fifty would be "60."
Place-Based Systems
Why are the numbers made from these symbols (of any radix) called place-based systems? The answer comes from the fact that every numeric representation is a string where the place represents a power in that radix from right to left.
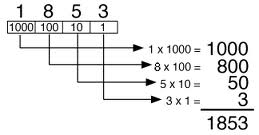
As you can see above, the simple decimal number 1853 has four places:
farthest to the right, the ones place 100
second to the right, the tens place 101
third from the right, the hundreds place 102
and fourth from the right, the thousands place 103
and the string ‘1853’ is thus a representation of a number using places to indicate powers.
A famous example of a numeral system that is not place-based is the Roman Numeral system. A Place-Based System applies not just with decimal, but with all the radix-based systems we see below.
Binary Place-Based Single Number Encoding System: 01
Standard coursework tells us of binary, a radix-2 system using (by definition) two symbols: '0' and '1'. In this base, the number 1 is '1', the number 2 is '10', the number 3 is '11', etc. This is the numeral system of computers and disks that provides the unifying clutch between voltage and symbolic logic, truth, turing machines, and computation.
Octal Place-Based Single Number Encoding System: 01234567
If we have a base-8 system, we can only use eight symbols. Reusing our first eight symbols from the base-10 system we get: 01234567. In this base, the number seven is 7, but the number eight is 10 because we have run out of symbols. We call these octal numbers. We should call them octal numerals.
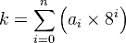
Hexadecimal Place-Based Single Number Encoding System: 0123456789ABCDEF
And what if we have more than 10 symbols? Hexadecimal, a base 16 system, is a good example of one. We commonly choose to use some letters from the latin alphabet (whether capitalized or not) as the 6 remaining symbols. Thus our alphabet of symbols in order is : 0123456789ABCDEF. In this base, the number 15 is F, and the number 16 is 10. Most people are familiar with hexadecimal numerals usage in RGB values. 
|
Tetrasexagesimal Place-Based Single Number Encoding System
For base64, we can use the lower-case alphabet and the upper-case alphabet: abcdefghijklmonpqrstuvwxyz and ABCDEFGHIJKLMNOPQRSTUVWXYZ. But this only gives us 26*2= 52 symbols, and we need 64 symbols. The symbol alphabet of numerals 0123456789 gives us ten more for a grand total of 62 symbols. We need to add two more.
For now, let's just choose the plus symbol '+' and the slash symbol '/'. Because we can order these symbols in any order we want, how about the following ordering?
Value Encoding Value Encoding Value Encoding Value Encoding
0 A 17 R 34 i 51 z
1 B 18 S 35 j 52 0
2 C 19 T 36 k 53 1
3 D 20 U 37 l 54 2
4 E 21 V 38 m 55 3
5 F 22 W 39 n 56 4
6 G 23 X 40 o 57 5
7 H 24 Y 41 p 58 6
8 I 25 Z 42 q 59 7
9 J 26 a 43 r 60 8
10 K 27 b 44 s 61 9
11 L 28 c 45 t 62 +
12 M 29 d 46 u 63 /
13 N 30 e 47 v
14 O 31 f 48 w
15 P 32 g 49 x
16 Q 33 h 50 y
In this base, the number seven is 'H', the number 50 is 'y', the number 62 is '+', and the number 64 is 'BA'.
But now, here is the big question: Is this the same base64 encoding that was used to pass binaries and dirty images on USENET posts? Is this the base64 that most languages, browsers, and email-clients support with library functions? Is this the base64 of RFC 4648?
The answer is a big fat NO. To explain why is not the same thing, we will make a digression and consider the notions of functions and types.
Functions and Types, Domains and Ranges
Types and functions are utterly fundamental to the art, science, and craft of programming.
One might say that types allow us to think about data, while functions allow us think about computation. Functions and types come clothed in different syntactical and run-time forms in any of your favorite language, but they are omnipresent and never to be discounted.
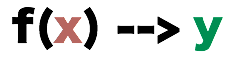 So why are we bringing them up? The answer is because we they will be helpful in explaining the difference between Place-Based Single Number Encoding and Concatenative Iterative Encoding.
So why are we bringing them up? The answer is because we they will be helpful in explaining the difference between Place-Based Single Number Encoding and Concatenative Iterative Encoding.
Up to now, we have been describing the notion of radix and base to represent a number, a system that we called Place-Based Single Number Encoding. To help us understand this encoding, let us describe it as a function with an input and an output.
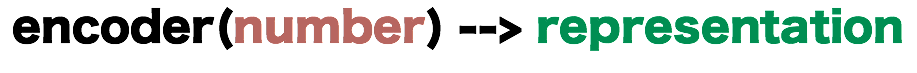 A representation is nothing more than a string of symbols in some alphabet.
A representation is nothing more than a string of symbols in some alphabet.
Thus, the number 101 is the decimal representation of the number “one hundred and one” while 65 is its hexadecimal representation. Both 101 and 65 are strings of symbols.
This is simplistic, but really exposes the essence of what we have been doing thus far. When we wanted to convert a single number into a binary representation we implicitly knew that the Domain of our function (our input type) was that of a number, and that the Range (the return type) was that of a string of zeros and ones. We can denote this function signature like this:
Ok. It feels like we burdened the obvious with theory. How does this help explain what email-based base64 encoding is? Well, the answer is to show the difference in their function signature, types and all.
What the base64 encoding of RFC 4648 does, and why it is different, is this:
It iteratively consumes an array of octets, transforms them into Base64 representations, and concatenates each representation into an output array.
In conclusion, we are saying one way of seeing the difference between these systems is by comparing their signatures
|
Place-Based Single Number Encoding
|
Concatenative Iterative Encoding System
|
Function
Signature
|
|
|
Does that clear it up?
Concatenative Iterative Encoding System
Yup, the term Concatenative Iterative Encoding sounds like a lot. But if we look at each word and examine its function signature, we will find it to be a description that is succinct and accurate.
Let's dissect both the term and the function signature, using the following visual of a file to motivate.
What we see above is a file (any file) represented as a long tape of zeros and ones. I have purposely colored four different groups of octets. Grouping bits into 8-bit chunks, called octets or bytes, makes it easier for us to think about the sheer number of zeros and ones. All files, whether text or not, are ultimately a concatenation of bits, so this is a valid way of understanding a file.
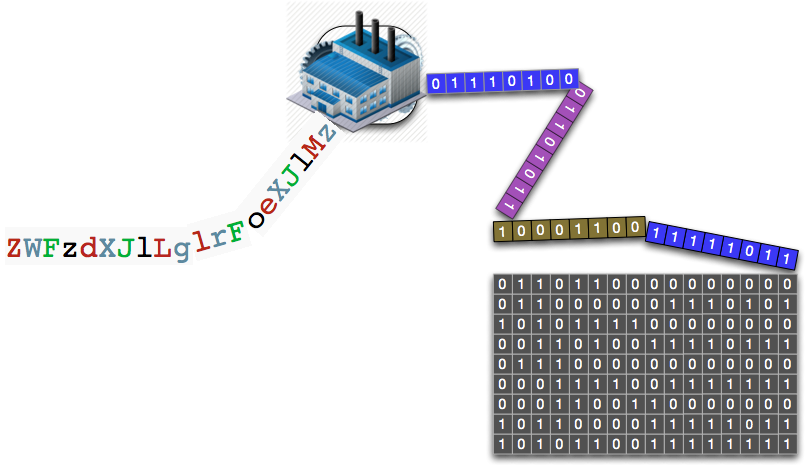 We can imagine the encoding function as a box that iteratively works its way down the tape, turning octets into base64 atoms. As the box/function moves its way down the tape, it slowly builds up the output tape by concatenating newly encoded base64 atoms. We are iteratively consuming octets from an array [OCTET] and concatenating them onto an output array of base64 representations [BASE64_REPRESENTATION].
We can imagine the encoding function as a box that iteratively works its way down the tape, turning octets into base64 atoms. As the box/function moves its way down the tape, it slowly builds up the output tape by concatenating newly encoded base64 atoms. We are iteratively consuming octets from an array [OCTET] and concatenating them onto an output array of base64 representations [BASE64_REPRESENTATION].
The implementation details of how we transform octets into numerals from a base64 are actually quite simple. I will go through them now, but the following sites provide more exhaustive descriptions:
-
-
We start with a stream of octets which means that we are grouping a stream of binary bits by 8 bits each.
 As you can see above, by merely choosing to put a grouping marker between every 8-bits, we can interpret this stream of 24 bits as 3 octets. Furthermore, we can choose to interpret each octet as the decimal numbers shown above, thus we see the numbers 77, 97, and 110. This example comes from the wikipedia article, showing how a text input could have been encoded, where the ASCII values for the word ‘Man’ are the input octets -- in ASCII ‘M’=77, ‘a’=97, and ‘n’=110.
As you can see above, by merely choosing to put a grouping marker between every 8-bits, we can interpret this stream of 24 bits as 3 octets. Furthermore, we can choose to interpret each octet as the decimal numbers shown above, thus we see the numbers 77, 97, and 110. This example comes from the wikipedia article, showing how a text input could have been encoded, where the ASCII values for the word ‘Man’ are the input octets -- in ASCII ‘M’=77, ‘a’=97, and ‘n’=110.
So what does base64 encoding do? Does it transform the input at all? No. It merely adjusts the grouping markers. Where before we grouped by 8 bits, now we will group by 6-bits.
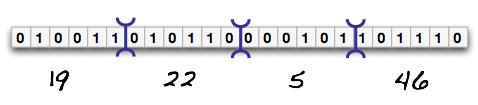 As you see above, we have reinterpreted 24-bits of data as 4 groups of 6-bits (sextets) rather than 3 groups of octets. Again, putting a decimal number for these new groups, we see the numbers 19, 22, 5, 46. But remember that base64 symbol table we had above? I will copy it down here again:
As you see above, we have reinterpreted 24-bits of data as 4 groups of 6-bits (sextets) rather than 3 groups of octets. Again, putting a decimal number for these new groups, we see the numbers 19, 22, 5, 46. But remember that base64 symbol table we had above? I will copy it down here again:
Value Encoding Value Encoding Value Encoding Value Encoding
0 A 17 R 34 i 51 z
1 B 18 S 35 j 52 0
2 C 19 T 36 k 53 1
3 D 20 U 37 l 54 2
4 E 21 V 38 m 55 3
5 F 22 W 39 n 56 4
6 G 23 X 40 o 57 5
7 H 24 Y 41 p 58 6
8 I 25 Z 42 q 59 7
9 J 26 a 43 r 60 8
10 K 27 b 44 s 61 9
11 L 28 c 45 t 62 +
12 M 29 d 46 u 63 /
13 N 30 e 47 v
14 O 31 f 48 w
15 P 32 g 49 x
16 Q 33 h 50 y
As we look at it, we can assign the number 19 to the base64 encoded numeral ‘T’, ‘W’=22, ‘F’=5, and ‘u’=46. Thus,
 a text file with the ASCII contents of ‘Man’ will result in a base64 encoding of ‘TWFu’.
a text file with the ASCII contents of ‘Man’ will result in a base64 encoding of ‘TWFu’.
Summing it all up
The Concatenative Iterative Encoding System has the following signature,
which in our particular example looks like:
 or equivalently
or equivalently
 And that is it. That is what base64 encoding does. It groups a stream of binary bits (grouped in 8-bit chunks) into a stream of output 6-bit sextets. Each sextet is interpreted as a single symbol from the radix-64 alphabet, and re-emitted as the ASCII representation of that symbol.
And that is it. That is what base64 encoding does. It groups a stream of binary bits (grouped in 8-bit chunks) into a stream of output 6-bit sextets. Each sextet is interpreted as a single symbol from the radix-64 alphabet, and re-emitted as the ASCII representation of that symbol.
Is it Compressions? No.
There always seems to be a major misapprehension of base64’s purpose, and one that we should try to clear up right now.
Base64 Encoding as a Concatenative Iterative Encoding System permits an arbitrary binary file to be translated into a string of text and copied in an email, or posted in a Usenet post. We have protected higher-level applications (like MIME) from arbitrary binary by choosing only letters that can exist within that application’s specification.
We have compressed the string length of symbols but we have not compressed the overall data size. In fact, we have actually inflated the size of the overall data payload by re-embedding the string ‘TWFu’ using ASCII.
Let us repeat the last statement: base64 does not compress the input data. In fact it inflates the size. It only compresses the length of the symbol string, by using an alphabet with more symbols.
|
A Final Comparison
|
Place-Based Single Number Encoding
|
Concatenative Iterative Encoding System
|
Function
Signature
|
|
|
Input Type
|
Single Number
|
Array of Octets
|
Output Type
|
representation of number in different radix
|
Array of Base64 representations
|
Consumption Direction
|
Right to Left
|
Left to Right
|
Used For
|
Representing a single number in a different radix, using a different alphabet consisting of different symbols.
|
Turning arbitrary binary into a left-to-right array of encoded characters that may be embedded and transferred within the context of an applications.
|
In the above chart there is one term that we have not yet discussed called “Consumption Direction”. The point of this is to show that Place-Based Single Number Encoding works on an entire number whose place-based format requires knowledge of the rightmost digit. To put it another way, you need to know the farthest right-most bits before you know what the number is.
On the other hand base64 as a Concatenative Iterative Encoding System consumes binary data from left to right. The reason for this is that base64 encoding usually operates on files which cannot always be loaded into memory. This is why we have subtly been referring to this algorithm as a streaming algorithm -- it does not have access to the entire input, but may start generating the output with only the first three octets. The actual physical implementation of reading bits from disk means that we always have access to the most significant bits (leftmost) before the least-significant bits (rightmost) are event loaded from disk.
The Place-Based Single Number Encoding is not appropriate for encoding a file because you would
need to load the file into memory to know its numeric representation
the number would be HUGE
On occasion, the two systems will produce the same answer. These occur when the number is bit-represented in multiples of 3-octets. If the number is slightly more than 3-octets, or only 2 or 1 octet, then the base64 specification calls for something called padding which adds zeros to the rightmost side. The effect of this is that base64 respects the leftmost/prefix data, while allowing the rightmost to be vastly different.
Padding is one of our hints that we are dealing with a streaming algorithm.
Finally, An Analysis of Crockford-base32 and its Implementations
The Crockford-base32 implementation has a few desirable properties that I will copy directly from the website:
The encoding scheme is required to
Be human readable and machine readable.
Be compact. Humans have difficulty in manipulating long strings of arbitrary symbols.
Be error resistant. Entering the symbols must not require keyboarding gymnastics.
Be pronounceable. Humans should be able to accurately transmit the symbols to other humans using a telephone.
|
Additionally, it tries to remove accidental obscenities and ambiguous looking symbols (like 0 and O).
I needed a Crockford32 implementation for Erlang but could not find one, so I looked up various implementations in other languages to try to understand what they did. I also looked closely at the base64 implementation that comes with the Erlang runtime. It was then that I figured out that the Crockford32 implementation implies Concatenative Iterative Encoding System but that all the implementations I could find are Place-Based Single Number Encoding.
The Conflicting Evidence
Evidence for thinking Crockford32 was meant to be a
Place-Based Single Number Encoding
|
Evidence for thinking Crockford32 was meant to be a
Concatenative Iterative Encoding System
|
All implementations use this assumption.
|
Zero implementations use this assumption.
|
The quote from the website saying,
“This document describes a 32-symbol notation for expressing numbers in a form that can be conveniently and accurately transmitted between humans and computer systems.”
Emphasis mine.
|
Quotes from the page that compare it in context with other Concatenative Iterative Encoding Systems
"Base 64 encoding uses a large symbol set containing both upper and lower case letters and many special characters. It is more compact than Base 16, but it is difficult to type and difficult to pronounce.”
“Base 32 seems the best balance between compactness and error resistance. Each symbol carries 5 bits.”
|
Language that implies that the primary use-case for this encoding is Human consumption which means short strings.
Short strings do not require streaming algorithms, as an entire number can absolutely be loaded into memory:
“Be pronounceable. Humans should be able to accurately transmit the symbols to other humans using a telephone.”
|
The most damning quote of all:
“If the bit-length of the number to be encoded is not a multiple of 5 bits, then zero-extend the number to make its bit-length a multiple of 5.”
This quote is absolutely about padding enough bits to the rightmost digits.
|
Conclusion
In the end, I think this has been a nice learning experience for me, and hopefully something worth sharing. Importantly, it drives home a few points:
most base32/16/64 encodings were designed to be streaming algorithms and operate only on octets and usually on a dataset that would not fit into memory
the recent explosion in services that want short-URLs while having unique identities for resources have increased the need for non-streaming radix-encoding algorithms
-
Finally, here is an Erlang implementation I wrote for Crockford-32 as a Place-Based Single Number Encoding.
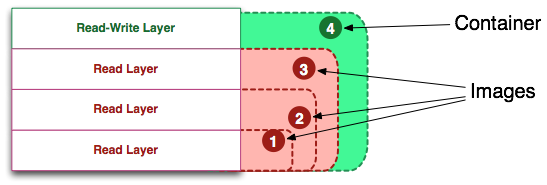
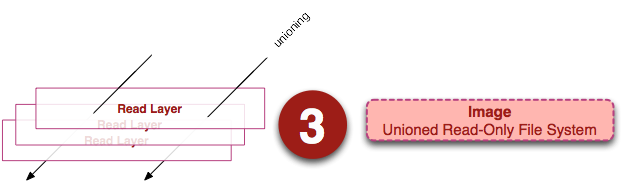
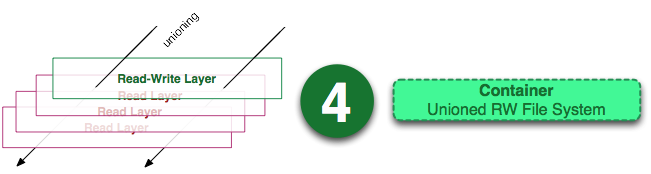
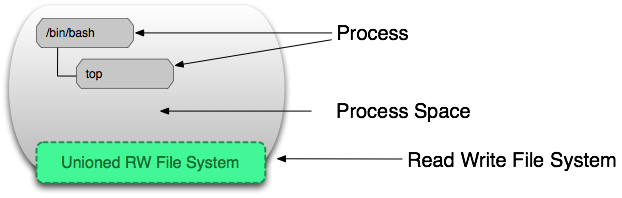
 This post is meant as a Docker 102-level post. If you are unaware of what Docker is, or don't know how it compares to virtual machines or to configuration management tools, then this post might be a bit too advanced at this time.
This post is meant as a Docker 102-level post. If you are unaware of what Docker is, or don't know how it compares to virtual machines or to configuration management tools, then this post might be a bit too advanced at this time.